How do experts design CNN's? How could I choose between Inception Modules, Dropout Regularization, Batch Normalization, convolutional filter size, size and depth of convolutional channels, number of fully-connected layers, activations neurons, etc? How do people navigate this large optimization problem in a scientific manner? The combinations are endless.
You said truly that the combinations are huge in number. And without approaching rightly you may end up with nowhere. A great one said machine Learning is an art, not science. Results are data-dependent. Here are a few tips regarding your above concern.
Log Everything: In the training time, save necessary logs of every experiment such as training loss, validation loss, weight files, execution times, visualization, etc. Some of them can be saved with CSVLogger, ModelCheckpoint etc. TensorBoard is a great tool for inspecting both training log and visualization and many more.
Strong Validation Strategies: This is very important. To build a stable Cross-Validation (CV), we must have a good understanding of the data and the challenges faced. We’ll check and make sure the validation set has a similar distribution to the training set and test set. And We’ll try to make sure our models improve both on our CV and on the test set (if gt is available for the test set). Basically, partitioning the data randomly is usually not enough to satisfy this. Understanding the data and how we can partition it without introducing a data leakage in our CV is key to avoid overfitting.
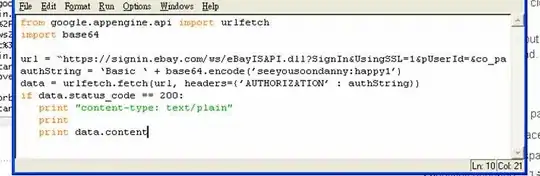
Change Only One: During the experiment, change one thing at a time and save the observations (logs) for those changes. For example: change the image size gradually from 224 (for example) to higher and observe the results. We should start with a small combination. While experimenting with image size, fix others like model architecture, learning rate, etc. The same goes for the learning rate part or model architectures. However, later we also may need to change more than one when we get some promising combinations. In kaggle competition, these are very common approaches one would follow. Below is a very simple example regarding this. But it's not limited any way.
However, as you said, your Ph.D. project is to reduce CO2 emissions on Earth. In my understanding, these are more application-specific problems and less than the algorithm-specific problems. So, we think it's better to take benefit from well-recognized pre-trained models.
In case if we wish to write our CNN on our own, we should give a decent time on it. Start with a very simple one, for example:
Conv2D (16, 3, 'relu') - > MaxPool (2)
Conv2D (32, 3, 'relu') - > MaxPool (2)
Conv2D (64, 3, 'relu') - > MaxPool (2)
Conv2D (128, 3, 'relu') - > MaxPool (2)
Here we gradually increase the depth but reducing the feature dimension. By the end layer, more semantic information would emerge. While stacking Conv2D layers, it's common practice to increase the channel depth in such order 16, 32, 64, 128 etc. If we want to impute Inception or Residual Block inside our network, I think, we should do some basic math first about what feature properties will come out of this, etc. Following a concept like this, we may also wish to look at approaches like SENet, ResNeSt etc. About Dropout, if we observe that our model is getting overfitted during training, then we should add some. In the final layer, we may want to choose GlobalAveragePooling over the Flatten layer (FCC). We can probably now understand that there are lots of ablation studies that need to be done to get a satisfactory CNN model.
In this regard, We suggest you explore the two most important things: (1). Read one of the pre-trained model papers/blogs/videos about their strategies to build the algorithm. For example: check out this EfficientNet Explained. (2). Next, explore the source code of it. That would give your more sense and encourage you to build your own giant.
We like to end this with one last working example. See the model diagram below, it's a small inception network, source. If we look closely, we will see, it consists of the following three modules.
- Conv Module
- Inception Module
- Downsample Modul
Take a close look at each module's configuration such as filter size, strides, etc. Let's try to understand and implement this module. Before that, here are two good references (1, 2) for the Inception concept to refresh the concept.
Conv Module
From the diagram we can see, it consists of one convolutional network, one batch normalization, and one relu activation. Also, it produces C times feature maps with K x K filters and S x S strides. To do that, we will create a class object that will inherit the tf.keras.layers.Layer classes
class ConvModule(tf.keras.layers.Layer):
def __init__(self, kernel_num, kernel_size, strides, padding='same'):
super(ConvModule, self).__init__()
# conv layer
self.conv = tf.keras.layers.Conv2D(kernel_num,
kernel_size=kernel_size,
strides=strides, padding=padding)
# batch norm layer
self.bn = tf.keras.layers.BatchNormalization()
def call(self, input_tensor, training=False):
x = self.conv(input_tensor)
x = self.bn(x, training=training)
x = tf.nn.relu(x)
return x
Inception Module
Next comes the Inception module. According to the above graph, it consists of two convolutional modules and then merges together. Now as we know to merge, here we need to ensure that the output feature maps dimension ( height and width ) needs to be the same.
class InceptionModule(tf.keras.layers.Layer):
def __init__(self, kernel_size1x1, kernel_size3x3):
super(InceptionModule, self).__init__()
# two conv modules: they will take same input tensor
self.conv1 = ConvModule(kernel_size1x1, kernel_size=(1,1), strides=(1,1))
self.conv2 = ConvModule(kernel_size3x3, kernel_size=(3,3), strides=(1,1))
self.cat = tf.keras.layers.Concatenate()
def call(self, input_tensor, training=False):
x_1x1 = self.conv1(input_tensor)
x_3x3 = self.conv2(input_tensor)
x = self.cat([x_1x1, x_3x3])
return x
Here you may notice that we are now hard-coded the exact kernel size and strides number for both convolutional layers according to the network (diagram). And also in ConvModule, we have already set padding to the same, so that the dimension of the feature maps will be the same for both (self.conv1 and self.conv2); which is required in order to concatenate them to the end.
Again, in this module, two variable performs as the placeholder, kernel_size1x1, and kernel_size3x3. This is for the purpose of course. Because we will need different numbers of feature maps to the different stages of the entire model. If we look into the diagram of the model, we will see that InceptionModule takes a different number of filters at different stages in the model.
Downsample Module
Lastly the downsampling module. The main intuition for downsampling is that we hope to get more relevant feature information that highly represents the inputs to the model. As it tends to remove the unwanted feature so that model can focus on the most relevant. There are many ways we can reduce the dimension of the feature maps (or inputs). For example: using strides 2 or using the conventional pooling operation. There are many types of pooling operation, namely: MaxPooling, AveragePooling, GlobalAveragePooling.
From the diagram, we can see that the downsampling module contains one convolutional layer and one max-pooling layer which later merges together. Now, if we look closely at the diagram (top-right), we will see that the convolutional layer takes a 3 x 3 size filter with strides 2 x 2. And the pooling layer (here MaxPooling) takes pooling size 3 x 3 with strides 2 x 2. Fair enough, however, we also ensure that the dimension coming from each of them should be the same in order to merge at the end. Now, if we remember when we design the ConvModule we purposely set the value of the padding argument to same. But in this case, we need to set it to valid.
class DownsampleModule(tf.keras.layers.Layer):
def __init__(self, kernel_size):
super(DownsampleModule, self).__init__()
# conv layer
self.conv3 = ConvModule(kernel_size, kernel_size=(3,3),
strides=(2,2), padding="valid")
# pooling layer
self.pool = tf.keras.layers.MaxPooling2D(pool_size=(3, 3),
strides=(2,2))
self.cat = tf.keras.layers.Concatenate()
def call(self, input_tensor, training=False):
# forward pass
conv_x = self.conv3(input_tensor, training=training)
pool_x = self.pool(input_tensor)
# merged
return self.cat([conv_x, pool_x])
Okay, now we have built all three modules, namely: ConvModule InceptionModule DownsampleModule. Let's initialize their parameter according to the diagram.
class MiniInception(tf.keras.Model):
def __init__(self, num_classes=10):
super(MiniInception, self).__init__()
# the first conv module
self.conv_block = ConvModule(96, (3,3), (1,1))
# 2 inception module and 1 downsample module
self.inception_block1 = InceptionModule(32, 32)
self.inception_block2 = InceptionModule(32, 48)
self.downsample_block1 = DownsampleModule(80)
# 4 inception module and 1 downsample module
self.inception_block3 = InceptionModule(112, 48)
self.inception_block4 = InceptionModule(96, 64)
self.inception_block5 = InceptionModule(80, 80)
self.inception_block6 = InceptionModule(48, 96)
self.downsample_block2 = DownsampleModule(96)
# 2 inception module
self.inception_block7 = InceptionModule(176, 160)
self.inception_block8 = InceptionModule(176, 160)
# average pooling
self.avg_pool = tf.keras.layers.AveragePooling2D((7,7))
# model tail
self.flat = tf.keras.layers.Flatten()
self.classfier = tf.keras.layers.Dense(num_classes, activation='softmax')
def call(self, input_tensor, training=True, **kwargs):
# forward pass
x = self.conv_block(input_tensor)
x = self.inception_block1(x)
x = self.inception_block2(x)
x = self.downsample_block1(x)
x = self.inception_block3(x)
x = self.inception_block4(x)
x = self.inception_block5(x)
x = self.inception_block6(x)
x = self.downsample_block2(x)
x = self.inception_block7(x)
x = self.inception_block8(x)
x = self.avg_pool(x)
x = self.flat(x)
return self.classfier(x)
The amount of filter number for each computational block is set according to the design of the model (see the diagram). After initialing all the blocks (in the __init__ function), we connect them according to the design (in the call function).

