I have a problem with a query in Oracle SQL.
I have a first_name column in an employees table. I want to group my records according to the first character in first_name.
For example, I have 26 records, one with name = 'Alice', one with name = 'Bob', and so on down the alphabet for each name's first character. After the query, there should be 26 groups with one employee each.
I tried the following, but it's not working:
SELECT employee_id, (SUBSTR(first_name,1,1)) AS alpha FROM employees
GROUP BY alpha;
name_which_starts_from employees
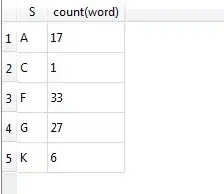
A 10
B 2
C 4
D 9
E 3
G 3
H 3
I 2
J 16
K 7
L 6
M 6
N 4
O 1
P 6
R 3
S 13
T 4
V 2
W 3