I'm a beginner to machine learning and have been trying to implement gradient descent to try and optimize the weights of my model. I am trying to develop the model from scratch and I have reviewed a lot of code online but my implementation still doesnt seem to decrease the loss of the model with the loss oscillating between 0.2 and 0.1. The loss function I used is L = (y - hypothesis)**2. Any help would be appreciated
for z in range(self.iterations):
print(z)
cost = 0
for x in range(self.batch_size):
derivatives = np.zeros(self.num_weights)
ran = self.random_row()
row = self.X.iloc[[ran]]
cost += self.loss(row, self.y[ran])
error = self.y[ran] - self.predict(row)
for i in range(len(derivatives)):
derivatives[i] = derivatives[i] + (error * (row.iloc[0,i] * -2))
derivatives[i] = derivatives[i] * learning_rate
self.weights[i] = self.weights[i] - derivatives[i]
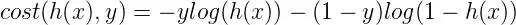
 .
.