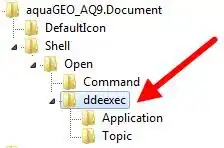
In my research I'm trying to tackle the Kolmogorov backward equation, i.e. interested in $$Af = b(x)f'(x)+\sigma(x)f''(x)$$
With the specific b(x) and \sigma(x), I'm trying to see how fast the coefficients of the expression are growing when calculating higher Af powers. I'm struggle to derive this analytically thus tried to see the trend empirically.
First, I have used sympy:
from sympy import *
import matplotlib.pyplot as plt
import re
import math
import numpy as np
import time
np.set_printoptions(suppress=True)
x = Symbol('x')
b = Function('b')(x)
g = Function('g')(x)
def new_coef(gamma, beta, coef_minus2, coef_minus1, coef):
return expand(simplify(gamma*coef_minus2 + beta*coef_minus1 + 2*gamma*coef_minus1.diff(x)\
+beta*coef.diff(x)+gamma*coef.diff(x,2)))
def new_coef_first(gamma, beta, coef):
return expand(simplify(beta*coef.diff(x)+gamma*coef.diff(x,2)))
def new_coef_second(gamma, beta, coef_minus1, coef):
return expand(simplify(beta*coef_minus1 + 2*gamma*coef_minus1.diff(x)\
+beta*coef.diff(x)+gamma*coef.diff(x,2)))
def new_coef_last(gamma, beta, coef_minus2):
return lambda x: gamma(x)*coef_minus2(x)
def new_coef_last(gamma, beta, coef_minus2):
return expand(simplify(gamma*coef_minus2 ))
def new_coef_second_to_last(gamma, beta, coef_minus2, coef_minus1):
return expand(simplify(gamma*coef_minus2 + beta*coef_minus1 + 2*gamma*coef_minus1.diff(x)))
def set_to_zero(expression):
expression = expression.subs(Derivative(b, x, x, x), 0)
expression = expression.subs(Derivative(b, x, x), 0)
expression = expression.subs(Derivative(g, x, x, x, x), 0)
expression = expression.subs(Derivative(g, x, x, x), 0)
return expression
def sum_of_coef(expression):
sum_of_coef = 0
for i in str(expression).split(' + '):
if i[0:1] == '(':
i = i[1:]
integers = re.findall(r'\b\d+\b', i)
if len(integers) > 0:
length_int = len(integers[0])
if i[0:length_int] == integers[0]:
sum_of_coef += int(integers[0])
else:
sum_of_coef += 1
else:
sum_of_coef += 1
return sum_of_coef
power = 6
charar = np.zeros((power, power*2), dtype=Symbol)
coef_sum_array = np.zeros((power, power*2))
charar[0,0] = b
charar[0,1] = g
coef_sum_array[0,0] = 1
coef_sum_array[0,1] = 1
for i in range(1, power):
#print(i)
for j in range(0, (i+1)*2):
#print(j, ':')
#start_time = time.time()
if j == 0:
charar[i,j] = set_to_zero(new_coef_first(g, b, charar[i-1, j]))
elif j == 1:
charar[i,j] = set_to_zero(new_coef_second(g, b, charar[i-1, j-1], charar[i-1, j]))
elif j == (i+1)*2-2:
charar[i,j] = set_to_zero(new_coef_second_to_last(g, b, charar[i-1, j-2], charar[i-1, j-1]))
elif j == (i+1)*2-1:
charar[i,j] = set_to_zero(new_coef_last(g, b, charar[i-1, j-2]))
else:
charar[i,j] = set_to_zero(new_coef(g, b, charar[i-1, j-2], charar[i-1, j-1], charar[i-1, j]))
#print("--- %s seconds for expression---" % (time.time() - start_time))
#start_time = time.time()
coef_sum_array[i,j] = sum_of_coef(charar[i,j])
#print("--- %s seconds for coeffiecients---" % (time.time() - start_time))
coef_sum_array
Then, looked into automated differentiation and used autograd:
import autograd.numpy as np
from autograd import grad
import time
np.set_printoptions(suppress=True)
b = lambda x: 1 + x
g = lambda x: 1 + x + x**2
def new_coef(gamma, beta, coef_minus2, coef_minus1, coef):
return lambda x: gamma(x)*coef_minus2(x) + beta(x)*coef_minus1(x) + 2*gamma(x)*grad(coef_minus1)(x)\
+beta(x)*grad(coef)(x)+gamma(x)*grad(grad(coef))(x)
def new_coef_first(gamma, beta, coef):
return lambda x: beta(x)*grad(coef)(x)+gamma(x)*grad(grad(coef))(x)
def new_coef_second(gamma, beta, coef_minus1, coef):
return lambda x: beta(x)*coef_minus1(x) + 2*gamma(x)*grad(coef_minus1)(x)\
+beta(x)*grad(coef)(x)+gamma(x)*grad(grad(coef))(x)
def new_coef_last(gamma, beta, coef_minus2):
return lambda x: gamma(x)*coef_minus2(x)
def new_coef_second_to_last(gamma, beta, coef_minus2, coef_minus1):
return lambda x: gamma(x)*coef_minus2(x) + beta(x)*coef_minus1(x) + 2*gamma(x)*grad(coef_minus1)(x)
power = 6
coef_sum_array = np.zeros((power, power*2))
coef_sum_array[0,0] = b(1.0)
coef_sum_array[0,1] = g(1.0)
charar = [b, g]
for i in range(1, power):
print(i)
charar_new = []
for j in range(0, (i+1)*2):
if j == 0:
new_funct = new_coef_first(g, b, charar[j])
elif j == 1:
new_funct = new_coef_second(g, b, charar[j-1], charar[j])
elif j == (i+1)*2-2:
new_funct = new_coef_second_to_last(g, b, charar[j-2], charar[j-1])
elif j == (i+1)*2-1:
new_funct = new_coef_last(g, b, charar[j-2])
else:
new_funct = new_coef(g, b, charar[j-2], charar[j-1], charar[j])
coef_sum_array[i,j] = new_funct(1.0)
charar_new.append(new_funct)
charar = charar_new
coef_sum_array
However, I'm so not happy with the speed of either of them. I would like to do at least thousand iterations while after 3 days of running simpy method, I got 30 :/
I expect that the second method (numerical) could be optimized to avoid recalculating expressions every time. Unfortunately, I cannot see that solution myself. Also, I have tried Maple, but again without luck.