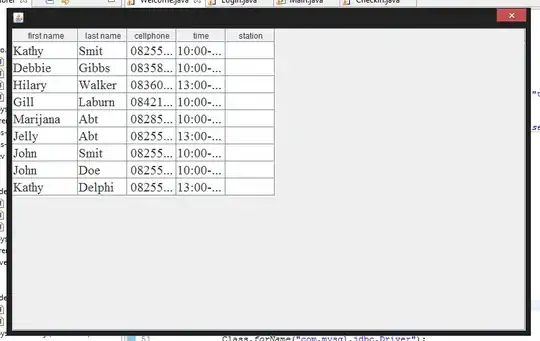
Sure, it's possible. However, seeing as how this particular page's DOM is populated asynchronously using JavaScript, BeautifulSoup won't be able to see the data you're trying to scrape. Normally, this is where most people would suggest you use a headless browser/webdriver like Selenium or PlayWright to simulate a browsing session - but you're in luck. You don't need headless browsers or Scrapestorm or BeautifulSoup for this particular page - you only need the third-party requests module. When you visit this page, it happens to make an HTTP GET request to a REST API that serves JSON. The JSON response contains all the information in the table. If you log your browser's network traffic, you can see the request made to the API:
Here is what the response JSON looks like - a list of dictionaries:

From that, you can copy the API URL and the relevant query string parameters to formulate your own request to that API:
def main():
import requests
url = "https://api.pantheon.world/person_ranks"
params = {
"select": "name,l,l_,age,non_en_page_views,coefficient_of_variation,hpi,hpi_prev,id,slug,gender,birthyear,deathyear,bplace_country(id,country,continent,slug),bplace_geonameid(id,place,country,slug,lat,lon),dplace_country(id,country,slug),dplace_geonameid(id,place,country,slug),occupation_id:occupation,occupation(id,occupation,occupation_slug,industry,domain),rank,rank_prev,rank_delta",
"birthyear": "gte.-3501",
"birthyear": "lte.2020",
"hpi": "gte.0",
"order": "hpi.desc.nullslast",
"limit": "50",
"offset": "0"
}
response = requests.get(url, params=params)
response.raise_for_status()
for person in response.json():
print(f"{person['name']} was a {person['occupation']['occupation']}")
return 0
if __name__ == "__main__":
import sys
sys.exit(main())
Output:
Muhammad was a RELIGIOUS FIGURE
Genghis Khan was a MILITARY PERSONNEL
Leonardo da Vinci was a INVENTOR
Isaac Newton was a PHYSICIST
Ludwig van Beethoven was a COMPOSER
Alexander the Great was a MILITARY PERSONNEL
Aristotle was a PHILOSOPHER
...
From here it's trivial to write this information to a CSV or excel file. You can play with the "limit": "50" and "offset": "0" key-value pairs in the params query string parameter dictionary, to retrieve information for different people.
EDIT - To get each person's thumbnail image, you need to construct a URL of the following form:
https://pantheon.world/images/profile/people/{PERSON_ID}.jpg
Where {PERSON_ID} is the value associated with the given person's id key:
...
for person in response.json():
image_url = f"https://pantheon.world/images/profile/people/{person['id']}.jpg"
print(f"{person['name']}'s image URL: {image_url}")
If you're using openpyxl for your excel files, here is a useful answer which shows you how you can insert an image into a cell given an image URL. I would recommend you use requests instead of urllib3, however, to make the request to the image.