It's possible to implement a dynamic solution, that allows to select apartments and users to see how many matches there are for the current selection.
But to achieve this we have to create a dimension per each of the columns to be used for the match and also divide some of them using ranges, in this case, the Budget/Price match columns. This is the model we want to create
and these are the dimension tables to be added for this particular example
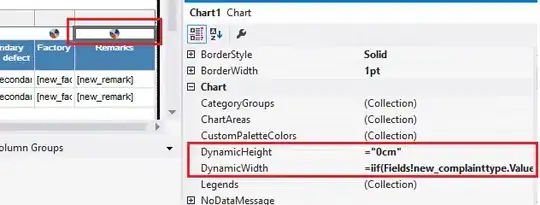
'Prices' table, with the Price ranges to be matced with the budget. The field to be used for the relationship is the PriceTo
Neighbouroods table
Numbers of Rooms table
Proximities to metro table, 1000 when not required (for users) or not available (for apartments)
Using these tables together with the original Users and Apartments, the dimensions, we can now create two calculated fact tables
Apartments Fact table
Apartments Fact =
SELECTCOLUMNS (
ALLNOBLANKROW ( Apartments ),
"Apartment ID", Apartments[Apartment ID],
"Price",
CALCULATE (
MAX ( Prices[PriceTo] ),
REMOVEFILTERS ( Prices ),
FILTER (
ALLNOBLANKROW ( Prices ),
Prices[PriceFrom] < Apartments[Price]
&& Prices[PriceTo] >= Apartments[Price]
)
),
"Neighbourhood", Apartments[Neghbourhood],
"Number of Rooms", Apartments[Number of Rooms],
"Prximity to metro station",
IF (
ISBLANK ( Apartments[Proximity to metro station] ),
1000,
Apartments[Proximity to metro station]
)
)
Users Fact table uses the CROSSJOIN to match all possible combinations of values for stacked fields and ranges, since budget is used as an upper limit
Users Fact =
SELECTCOLUMNS (
GENERATE (
SELECTCOLUMNS (
Users,
"User ID", Users[User ID],
"UsersNeighbourhoods", Users[Neigbourhoods],
"UserNumberOfRooms", Users[Number of rooms],
"UserProximityToMetroStation", Users[Proximity to metro station],
"UserBudget", Users[Budget]
),
VAR PricesTable =
SELECTCOLUMNS (
FILTER (
ALLNOBLANKROW ( Prices ),
Prices[PriceTo] <= [UserBudget]
),
"Price", [PriceTo]
)
VAR Neighbouroods =
FILTER (
ALLNOBLANKROW ( Neighbourhoods[Neighbourhood] ),
CONTAINSSTRING (
[UsersNeighbourhoods],
Neighbourhoods[Neighbourhood]
)
)
VAR Rooms =
FILTER (
ALLNOBLANKROW ( 'Numbers of rooms'[Number of rooms] ),
CONTAINSSTRING (
[UserNumberOfRooms],
'Numbers of rooms'[Number of rooms]
)
)
VAR Proximity =
FILTER (
ALLNOBLANKROW ( 'Proximities to metro station'[Proximity to metro station] ),
'Proximities to metro station'[Proximity to metro station]
<= IF (
ISBLANK ( [UserProximityToMetroStation] ),
10000,
[UserProximityToMetroStation]
)
)
VAR CorssjoinedTable =
CROSSJOIN (
CROSSJOIN (
CROSSJOIN (
PricesTable,
Neighbouroods
),
Rooms
),
Proximity
)
RETURN
CorssjoinedTable
),
"User ID", [User ID],
"Price", [Price],
"Neighbourhood", [Neighbourhood],
"Proximity to metro station", [Proximity to metro station],
"Number of rooms", [Number of rooms]
)
Once we have the fact tables we can create the relationship with the dimensions to get the model of the previous image.
It's now possible to define the two measure that can compute dynamically the numbers of matching users and apartments
We use the expanded tables to propagate the filters from the fact tables to the dimension, twice, since we need to propagate the filters through two fact tables
First from Aparmtents to Users
# Users =
CALCULATE (
COUNTROWS ( Users ),
CALCULATETABLE (
'Users Fact',
'Apartments Fact'
)
)
Then from Users to Apartments
# Apartments =
CALCULATE (
COUNTROWS ( Apartments ),
CALCULATETABLE (
'Apartments Fact',
'Users Fact'
)
)
We can also implement a measure returning a string with the matching apartments for the user
Apartments Match =
CALCULATE (
CONCATENATEX (
Apartments,
Apartments[Apartment ID],
", "
),
CALCULATETABLE (
'Apartments Fact',
'Users Fact'
)
)
And of the users for the current apartment
UsersMatch =
CALCULATE (
CONCATENATEX (
Users,
Users[User ID],
", "
),
CALCULATETABLE (
'Users Fact',
'Apartments Fact'
)
)
Since this technique creates fact tables using crossjoins, the cardinality can grow really fast and might become a problem when Users and Aparment sizes become important. One way to reduce the number of rows generated can be to use ranges with larger intervals, or maybe to implement something different :)
I hope I didn't make too many mistakes, since this answer got a bit longer than what I thought and I had to write it a bit in a hurry.