It is using an Index Scan primarily because it is also using a Merge Join. The Merge Join operator requires two input streams that are both sorted in an order that is compatible with the Join conditions.
And it is using the Merge Join operator to realize your INNER JOIN because it believes that that will be faster than the more typical Nested Loop Join operator. And it is probably right (it usually is), by using the two indexes it has chosen, it has input streams that are both pre-sorted according your join condition (LocationID). When the input streams are pre-sorted like this, then Merge Joins are almost always faster than the other two (Loop and Hash Joins).
The downside is what you have noticed: it appears to be scanning the whole index in, so how can that be faster if it is reading so many records that may never be used? The answer is that Scans (because of their sequential nature) can read anywhere from 10 to 100 times as many records/second as seeks.
Now Seeks usually win because they are selective: they only get the rows that you ask for, whereas Scans are non-selective: they must return every row in the range. But because Scans have a much higher read rate, they can frequently beat Seeks as long as the ratio of Discarded Rows to Matching Rows is lower than the ratio of Scan rows/sec VS. Seek rows/sec.
Questions?
OK, I have been asked to explain the last sentence more:
A "Discarded Row" is one that the the Scan reads (because it has to read everything in the index), but that will be rejected by the Merge Join operator, because it does not have a match on the other side, possibly because the WHERE clause condition has already excluded it.
"Matching Rows" are the ones that it read that are actually matched to something in the Merge Join. These are the same rows that would have been read by a Seek if the Scan were replaced by a Seek.
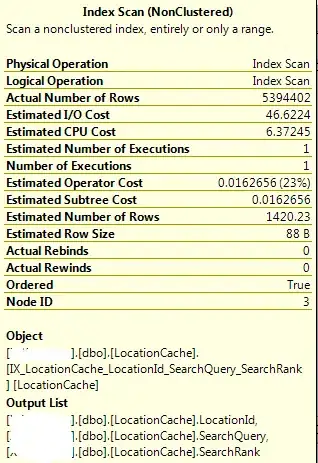
You can figure out what there are by looking at the statistics in the Query Plan. See that huge fat arrow to the left of the Index Scan? That represents how many rows the optimizer thinks that it will read with the Scan. The statistics box of the Index Scan that you posted shows the Actual Rows returned is about 5.4M (5,394,402). This is equal to:
TotalScanRows = (MatchingRows + DiscardedRows)
(In my terms, anyway). To get the Matching Rows, look at the "Actual Rows" reported by the Merge Join operator (you may have to take off the TOP 100 to get this accurately). Once you know this, you can get the Discarded rows by:
DiscardedRows = (TotalScanRows - MatchingRows)
And now you can calculate the ratio.