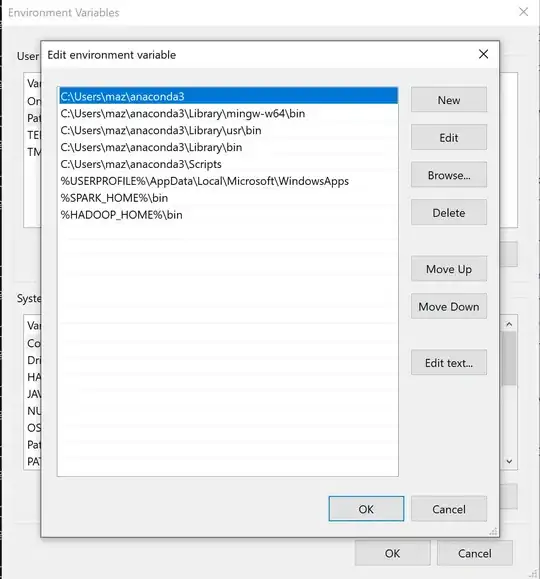
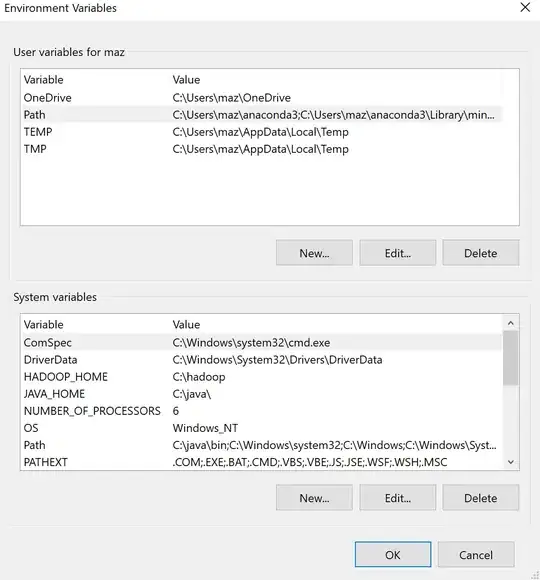
I am trying to install pretrained pipelines in spark-nlp in windows 10 with python. The following is the code I have tried so far in the Jupyter notebook in the local system:
! java -version
# should be Java 8 (Oracle or OpenJDK)
! conda create -n sparknlp python=3.7 -y
! conda activate sparknlp
! pip install --user spark-nlp==2.6.4 pyspark==2.4.5
from sparknlp.base import *
from sparknlp.annotator import *
from sparknlp.pretrained import PretrainedPipeline
import sparknlp
# Start Spark Session with Spark NLP
# start() functions has two parameters: gpu and spark23
# sparknlp.start(gpu=True) will start the session with GPU support
# sparknlp.start(sparrk23=True) is when you have Apache Spark 2.3.x installed
spark = sparknlp.start()
# Download a pre-trained pipeline
pipeline = PretrainedPipeline('explain_document_ml', lang='en')
I am getting the following error:
explain_document_ml download started this may take some time.
Approx size to download 9.4 MB
[OK!]
---------------------------------------------------------------------------
Py4JJavaError Traceback (most recent call last)
~\AppData\Roaming\Python\Python37\site-packages\pyspark\sql\utils.py in deco(*a, **kw)
62 try:
---> 63 return f(*a, **kw)
64 except py4j.protocol.Py4JJavaError as e:
~\Anaconda3\envs\py37\lib\site-packages\py4j\protocol.py in get_return_value(answer, gateway_client, target_id, name)
327 "An error occurred while calling {0}{1}{2}.\n".
--> 328 format(target_id, ".", name), value)
329 else:
Py4JJavaError: An error occurred while calling z:com.johnsnowlabs.nlp.pretrained.PythonResourceDownloader.downloadPipeline.
: java.lang.IllegalArgumentException: requirement failed: Was not found appropriate resource to download for request: ResourceRequest(explain_document_ml,Some(en),public/models,2.6.4,2.4.4) with downloader: com.johnsnowlabs.nlp.pretrained.S3ResourceDownloader@2570f26e
at scala.Predef$.require(Predef.scala:224)
at com.johnsnowlabs.nlp.pretrained.ResourceDownloader$.downloadResource(ResourceDownloader.scala:345)
at com.johnsnowlabs.nlp.pretrained.ResourceDownloader$.downloadPipeline(ResourceDownloader.scala:376)
at com.johnsnowlabs.nlp.pretrained.ResourceDownloader$.downloadPipeline(ResourceDownloader.scala:371)
at com.johnsnowlabs.nlp.pretrained.PythonResourceDownloader$.downloadPipeline(ResourceDownloader.scala:474)
at com.johnsnowlabs.nlp.pretrained.PythonResourceDownloader.downloadPipeline(ResourceDownloader.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Unknown Source)
During handling of the above exception, another exception occurred:
IllegalArgumentException Traceback (most recent call last)
<ipython-input-2-d18238e76d9f> in <module>
11
12 # Download a pre-trained pipeline
---> 13 pipeline = PretrainedPipeline('explain_document_ml', lang='en')
~\Anaconda3\envs\py37\lib\site-packages\sparknlp\pretrained.py in __init__(self, name, lang, remote_loc, parse_embeddings, disk_location)
89 def __init__(self, name, lang='en', remote_loc=None, parse_embeddings=False, disk_location=None):
90 if not disk_location:
---> 91 self.model = ResourceDownloader().downloadPipeline(name, lang, remote_loc)
92 else:
93 self.model = PipelineModel.load(disk_location)
~\Anaconda3\envs\py37\lib\site-packages\sparknlp\pretrained.py in downloadPipeline(name, language, remote_loc)
58 t1.start()
59 try:
---> 60 j_obj = _internal._DownloadPipeline(name, language, remote_loc).apply()
61 jmodel = PipelineModel._from_java(j_obj)
62 finally:
~\Anaconda3\envs\py37\lib\site-packages\sparknlp\internal.py in __init__(self, name, language, remote_loc)
179 class _DownloadPipeline(ExtendedJavaWrapper):
180 def __init__(self, name, language, remote_loc):
--> 181 super(_DownloadPipeline, self).__init__("com.johnsnowlabs.nlp.pretrained.PythonResourceDownloader.downloadPipeline", name, language, remote_loc)
182
183
~\Anaconda3\envs\py37\lib\site-packages\sparknlp\internal.py in __init__(self, java_obj, *args)
127 super(ExtendedJavaWrapper, self).__init__(java_obj)
128 self.sc = SparkContext._active_spark_context
--> 129 self._java_obj = self.new_java_obj(java_obj, *args)
130 self.java_obj = self._java_obj
131
~\Anaconda3\envs\py37\lib\site-packages\sparknlp\internal.py in new_java_obj(self, java_class, *args)
137
138 def new_java_obj(self, java_class, *args):
--> 139 return self._new_java_obj(java_class, *args)
140
141 def new_java_array(self, pylist, java_class):
~\AppData\Roaming\Python\Python37\site-packages\pyspark\ml\wrapper.py in _new_java_obj(java_class, *args)
65 java_obj = getattr(java_obj, name)
66 java_args = [_py2java(sc, arg) for arg in args]
---> 67 return java_obj(*java_args)
68
69 @staticmethod
~\Anaconda3\envs\py37\lib\site-packages\py4j\java_gateway.py in __call__(self, *args)
1255 answer = self.gateway_client.send_command(command)
1256 return_value = get_return_value(
-> 1257 answer, self.gateway_client, self.target_id, self.name)
1258
1259 for temp_arg in temp_args:
~\AppData\Roaming\Python\Python37\site-packages\pyspark\sql\utils.py in deco(*a, **kw)
77 raise QueryExecutionException(s.split(': ', 1)[1], stackTrace)
78 if s.startswith('java.lang.IllegalArgumentException: '):
---> 79 raise IllegalArgumentException(s.split(': ', 1)[1], stackTrace)
80 raise
81 return deco
IllegalArgumentException: 'requirement failed: Was not found appropriate resource to download for request: ResourceRequest(explain_document_ml,Some(en),public/models,2.6.4,2.4.4) with downloader: com.johnsnowlabs.nlp.pretrained.S3ResourceDownloader@2570f26e'