I'm running a job on AI Platform and it's running for over an hour with no progress, no results, no logs(only few logs showing it's running)
Here is the region, machine type, gpus I was using:
"region": "us-central1",
"runtimeVersion": "2.2",
"pythonVersion": "3.7",
"masterConfig": {
"acceleratorConfig": {
"count": "8",
"type": "NVIDIA_TESLA_K80"
}
}
the AI Platform job
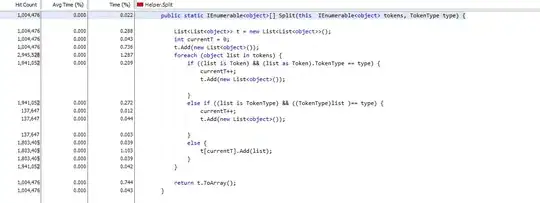
only few logs for this job

The model I'm training is big and uses a lot of memory. The job is just hanging there without any progress, logs or errors. But I notice that it's consumed 12.81 ML units on GCP. Normally, if the GPU is running out of memory, it would throw an "OOM/resourceExhausted error". Without logs, I have no idea what's wrong there.
I ran a different job with smaller dimension of the input and it completed successfully in 12 mins:
successed job
Also, I use tf.MirroredStrategy for the training process so that it can distribute across GPUs.
Any thoughts on this?