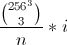I have a table with the total number of secondary IDs per each principal ID. So I need to generate a second table in which each row correspond to the combination of primary ID and Secondary ID. For example if for primary ID1 I have 5 as the number of secondary ids I would need 5 rows, each with the same Primary ID and the second ID going from 1 to 5. Doing this with a loop takes a lot of time so I was wondering if there is a more efficient way of doing this without involving loops.
Visual example:
Table
Table Output