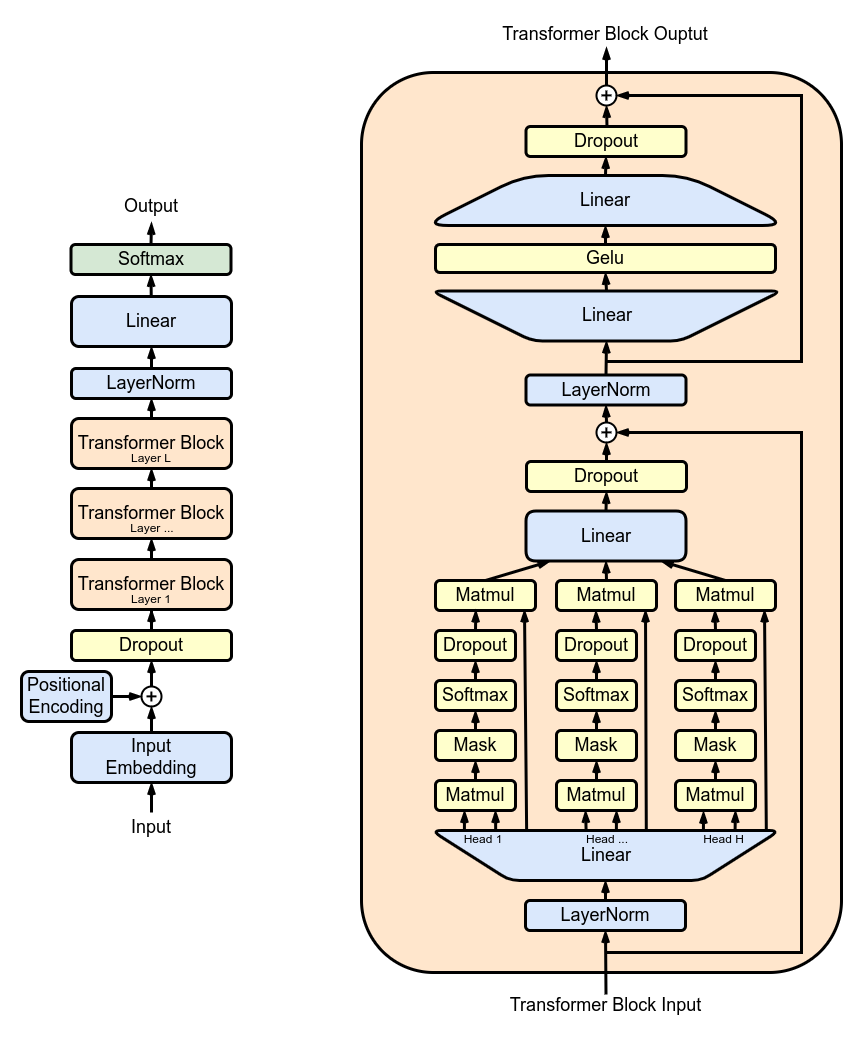
I have seen two different implementations of Multi-Head Attention.
- In one of the approaches the queries, keys and values are split into heads before being passed through the linear layers as shown below:
def split_heads(self, x, batch_size):
return x.reshape(batch_size, -1, self.heads, self.projection_dim)
def forward(self, queries, keys, values, mask):
batch_size = queries.size()[0]
# split queries keys and values into heads
queries = self.split_heads(queries, batch_size)
keys = self.split_heads(keys, batch_size)
values = self.split_heads(values, batch_size)
queries = self.queries_linear(queries)
keys = self.keys_linear(keys)
values = self.values_linear(values)
#...more code
- The second approach is to split the queries, keys and values into heads after passing them through linear layers:
def forward(self, queries, keys, values, mask=None):
batch_size = q.size(0)
# perform linear operation and split into h heads
k = self.keys_linear(keys).view(batch_size, -1, self.heads, self.projection_dim)
q = self.queries_linear(queries).view(batch_size, -1, self.heads, self.projection_dim)
v = self.values_linear(values).view(batch_size, -1, self.heads, self.projection_dim)
#...more code
According to the paper Attention Is All You Need, from what I can deduce from the image the queries and keys should be split before being passed through the linear layers, but from most implementation online they are split after. 
Are the two approaches similar or is one better than the other?
{kind=link}