Link to the document on scikit-learn: link
What it essentially does is, it normalizes the data such that each data point falls under a bucket between 0 and 1 (percentile rank?) and I assume each of these buckets would have equal number of data points. This image describes what I am trying to do.
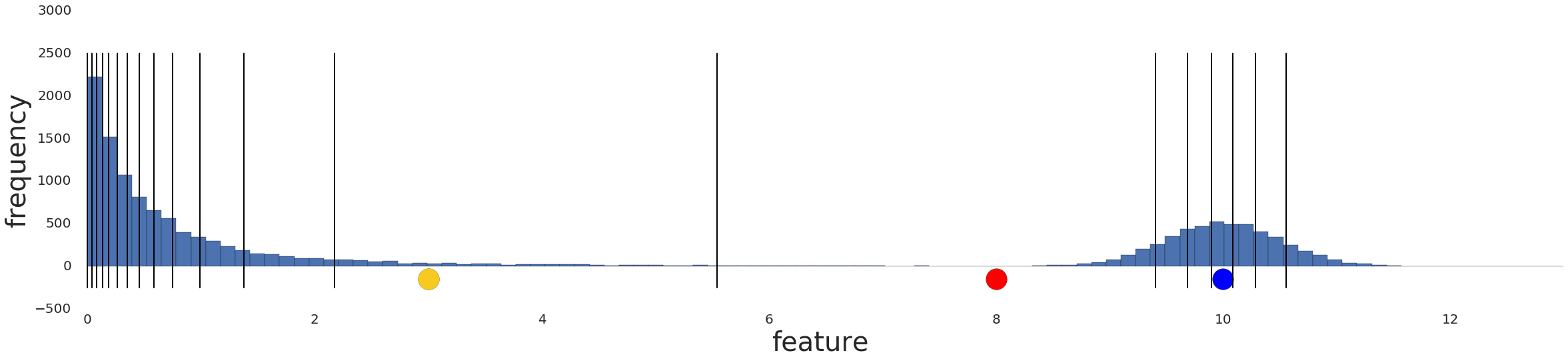{kind=link}
I would like to use this Quantile transformation with PySpark. There is a QuantileDiscretizer link in PySpark, but it doen't exactly do what I am looking for. It also returns less number of buckets than given in the input parameters. The below line of code returns only 81 distinct buckets on a data set with millions of rows, and min(col_1) as 0 and max(col_1) as 20000.
discretizer_1 = QuantileDiscretizer(numBuckets=100, inputCol="col_1", outputCol="result")
So is there a way I can uniformly normalize my data, either using QuantileDiscretizer or otherwise using PySpark?