Looking at your example input:
# This is the most simple configuration
title = "FML rulez"
# We use ISO notations only, so no local styles
releaseDateTime = 2020-09-12T06:34
# Multiline strings
description = "So,
I'm curious
where this will end."
# Shorcut string; no quotes are needed in a simple property style assignment
# Or if a string is just one word. These strings are trimmed.
protocol = http
# Conditions allow for overriding, best match wins (most conditions)
# If multiple condition sets equally match, the first one will win.
title[env=production] = "One config file to rule them all"
title[env=production & os=osx] = "Even on Mac"
# Lists
hosts = [alpha, beta]
# Hierarchy is implemented using groups denoted by curly brackets
database {
# indenting is allowed and encouraged, but has no semantic meaning
url = jdbc://...
user = "admin"
# Strings support default encryption with a external key file, like maven
password = "FGFGGHDRG#$BRTHT%G%GFGHFH%twercgfg"
# groups can nest
dialect {
database = postgres
}
}
servers {
# This is a table:
# - the first row is a header, containing the id's
# - the remaining rows are values
| name | datacenter | maxSessions | settings |
| alpha | A | 12 | |
| beta | XYZ | 24 | |
| "sys 2" | B | 6 | |
# you can have sub blocks, which are id-less groups (id is the column)
| gamma | C | 12 | {breaker:true, timeout: 15} |
# or you reference to another block
| tango | D | 24 | $environment |
}
# environments can be easily done using conditions
environment[env=development] {
datasource = tst
}
environment[env=production] {
datesource = prd
}
I'd go for something like this:
grammar TECL;
input_file
: configs EOF
;
configs
: NL* ( config ( NL+ config )* NL* )?
;
config
: property
| group
| table
;
property
: WORD conditions? ASSIGN value
;
group
: WORD conditions? NL* OBRACE configs CBRACE
;
conditions
: OBRACK property ( AMP property )* CBRACK
;
table
: row ( NL+ row )*
;
row
: PIPE ( col_value PIPE )+
;
col_value
: ~( PIPE | NL )*
;
value
: WORD
| VARIABLE
| string
| list
;
string
: STRING
| WORD+
;
list
: OBRACK ( value ( COMMA value )* )? CBRACK
;
ASSIGN : '=';
OBRACK : '[';
CBRACK : ']';
OBRACE : '{';
CBRACE : '}';
COMMA : ',';
PIPE : '|';
AMP : '&';
VARIABLE
: '$' WORD
;
NL
: [\r\n]+
;
STRING
: '"' ( ~[\\"] | '\\' . )* '"'
;
WORD
: ~[ \t\r\n[\]{}=,|&]+
;
COMMENT
: '#' ~[\r\n]* -> skip
;
SPACES
: [ \t]+ -> skip
;
which will parse the example in the following parse tree:
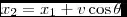
And the input:
key = value
key = spaces are allowed
key = until a new line or a comment # this is a comment
key = "you can use quotes as well" # this is a comment
key = "and
with quotes
you can also do
multiline"
into the following:
For now: multiline quoted works, spaces in unquoted string not.
As you can see in the tree above, it does work. I suspect you used part of the grammar in your existing one and that doesn't work.
[...] and am I the process inserting the actions.
I would not embed actions (target code) inside your grammar: it makes it hard to read, and making changes to the grammar will be harder to do. And of course, your grammar will only work for 1 language. Better use a listener or visitor instead of these actions.
Good luck!

