I am trying to understand the concept of IOU in YOLO. I read that it is the area of overlap between the predicted bounding box and the ground-truth bounding box. This is needed for training the data and you manually place the ground truth bounding box. My question is if you want to apply YOLO on new images, how does it know the ground truth bounding box?
Asked
Active
Viewed 6,396 times
1 Answers
6
If we have two bounding boxes, then, IoU is defined as
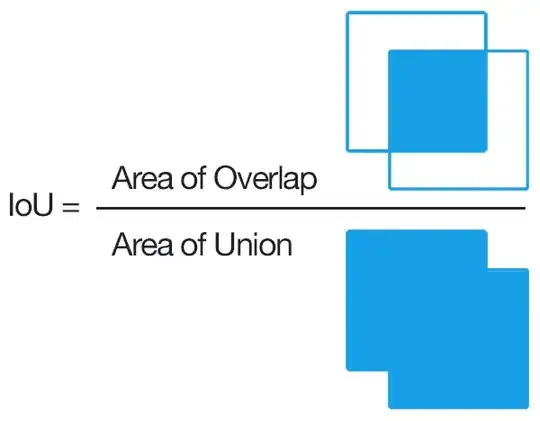
It is used for two purposes:
It helps us benchmark the accuracy of our model predictions. Using it, we can figure out how well does our predicted bounding box overlap with the ground truth bounding box. The higher the IoU, the better the performance. The results can be interpreted as

It helps us remove duplicate bounding boxes for the same object. For, this, we sort all the predictions/objects in descending order of their confidence. If two bounding boxes are pointing to the same object, their IoU would definitely be very high. In this case, we choose the box with higher confidence (i.e., the first box) and reject the second one. If the IoU is very low, this would possibly mean that the two boxes point to different objects of the same class(like different dogs or different cats in the same picture).
What you refer to, is the first part, checking the accuracy of your model/predictions. It should be noted that this step is done at the learning phase and specifically, at completion of training. The dataset is split into training set and validation set. The validation dataset is the one used to check the performance, and as you said, the ground truth boxes are manually provided by the user.
This is not done after the model has completed training and is being used/deployed. At this time, we use the second application of IoU and use it to remove duplicate bounding boxes.
Pe Dro
- 2,651
- 3
- 24
- 44