I am developing a language model like https://pytorch.org/tutorials/beginner/transformer_tutorial.html.
It is not clear for me - whether positional encoding is neccessary here ? As far as I understand - it is necessary for language translation task because the decoder should be able to position the word from the previous output within the sequence from encoder. But is it necessary in language modeling without the decoder ?
Is it possible that the words in the encoder output are shuffled ?
Edit:
there are no explanations in the original paper. And I didn't find explanations in tutorials (like here https://kazemnejad.com/blog/transformer_architecture_positional_encoding/).
I don't understand this:
"As each word in a sentence simultaneously flows through the Transformer’s encoder/decoder stack, The model itself doesn’t have any sense of position/order for each word."
From my point of view - transformer encoder has info about the order because its input is an ordered sequence (similar to RNN).
I tried to remove positional encoding from the model. It works, but with a worse performance.
Is it useful to add such positional encoding to RNN ? Could it improve its performance ?
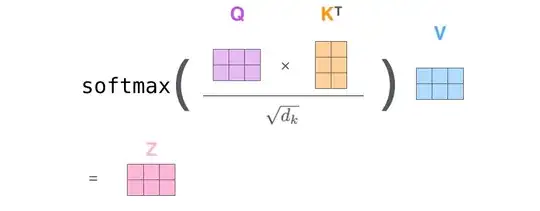 Taken from
Taken from