The obvious space-save I don't know how to do:
- Not writing out duplicate vertices. In total, there are around 8x more vertices in the file than there should be. However, fixing this is extremely tricky because objects in Wavefront Object files do not use per-object, but global vertices. By writing out all 8 vertices each time, I always know which 8 vertices make up the next voxel. If I do not write out all 8, how do I keep track of which place in the global list I can find those 8 (if at all).
This is something I once did in the past to prepare meshes (out of loaded geometry) for OpenGL buffers. For this, I intended to remove duplicates from vertices as an index buffer was already planned.
This is what I did: Insert all vertices in a std::set which will eliminate duplicates.
To lower the memory consumption, I used a std::set with index type (e.g. size_t or unsigned) with a custom predicate which does the comparison on the indexed coordinates.
The custom less predicate:
// functor for less predicate comparing indexed values
template <typename VALUE, typename INDEX>
struct LessValueT {
VALUE *values;
LessValueT(std::vector<VALUE> &values): values(values.data()) { }
bool operator()(INDEX i1, INDEX i2) const { return values[i1] < values[i2]; }
};
and the std::set with this predicate:
// an index table (sorting indices by indexed values)
template <typename VALUE, typename INDEX>
using LookUpTableT = std::set<INDEX, LessValueT<VALUE, INDEX>>;
To use the above with coordinates (or normals) which are stored e.g. as
template <typename VALUE>
struct Vec3T { VALUE x, y, z; };
it is necessary to overload the less operator accordingly which I did in the most naïve way for this sample:
template <typename VALUE>
bool operator<(const Vec3T<VALUE> &vec1, const Vec3T<VALUE> &vec2)
{
return vec1.x < vec2.x ? true : vec1.x > vec2.x ? false
: vec1.y < vec2.y ? true : vec1.y > vec2.y ? false
: vec1.z < vec2.z;
}
Thereby, it is not necessary to think about sense or non-sense of the order which results from this predicate. It just must fit into the requirements of the std::set to distinguish and sort vector values with differing components.
To demonstrate this, I use a tetrix sponge:
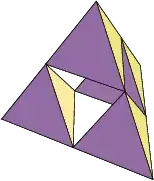
It is easy to build with varying number of triangles (depending on sub-division levels) and resembles IMHO quite good the assumptions I did about OPs data:
- a significant number of shared vertices
- a small number of different normals.
The complete sample code testCollectVtcs.cc:
#include <cassert>
#include <cmath>
#include <chrono>
#include <fstream>
#include <functional>
#include <iostream>
#include <numeric>
#include <set>
#include <string>
#include <vector>
namespace Compress {
// functor for less predicate comparing indexed values
template <typename VALUE, typename INDEX>
struct LessValueT {
VALUE *values;
LessValueT(std::vector<VALUE> &values): values(values.data()) { }
bool operator()(INDEX i1, INDEX i2) const { return values[i1] < values[i2]; }
};
// an index table (sorting indices by indexed values)
template <typename VALUE, typename INDEX>
using LookUpTableT = std::set<INDEX, LessValueT<VALUE, INDEX>>;
} // namespace Compress
// the compress function - modifies the values vector
template <typename VALUE, typename INDEX = size_t>
std::vector<INDEX> compress(std::vector<VALUE> &values)
{
typedef Compress::LessValueT<VALUE, INDEX> LessValue;
typedef Compress::LookUpTableT<VALUE, INDEX> LookUpTable;
// collect indices and remove duplicate values
std::vector<INDEX> idcs; idcs.reserve(values.size());
LookUpTable lookUp((LessValue(values)));
INDEX iIn = 0, nOut = 0;
for (const INDEX n = values.size(); iIn < n; ++iIn) {
values[nOut] = values[iIn];
std::pair<LookUpTable::iterator, bool> ret = lookUp.insert(nOut);
if (ret.second) { // new index added?
++nOut; // remark value as stored
}
idcs.push_back(*ret.first); // store index
}
// discard all obsolete values
values.resize(nOut);
// done
return idcs;
}
// instrumentation to take times
typedef std::chrono::high_resolution_clock Clock;
typedef std::chrono::microseconds USecs;
typedef decltype(std::chrono::duration_cast<USecs>(Clock::now() - Clock::now())) Time;
Time duration(const Clock::time_point &t0)
{
return std::chrono::duration_cast<USecs>(Clock::now() - t0);
}
Time stopWatch(std::function<void()> func)
{
const Clock::time_point t0 = Clock::now();
func();
return duration(t0);
}
// a minimal linear algebra tool set
template <typename VALUE>
struct Vec3T { VALUE x, y, z; };
template <typename VALUE>
Vec3T<VALUE> operator*(const Vec3T<VALUE> &vec, VALUE s) { return { vec.x * s, vec.y * s, vec.z * s }; }
template <typename VALUE>
Vec3T<VALUE> operator*(VALUE s, const Vec3T<VALUE> &vec) { return { s * vec.x, s * vec.y, s * vec.z }; }
template <typename VALUE>
Vec3T<VALUE> operator+(const Vec3T<VALUE> &vec1, const Vec3T<VALUE> &vec2)
{
return { vec1.x + vec2.x, vec1.y + vec2.y, vec1.z + vec2.z };
}
template <typename VALUE>
Vec3T<VALUE> operator-(const Vec3T<VALUE> &vec1, const Vec3T<VALUE> &vec2)
{
return { vec1.x - vec2.x, vec1.y - vec2.y, vec1.z - vec2.z };
}
template <typename VALUE>
VALUE length(const Vec3T<VALUE> &vec)
{
return std::sqrt(vec.x * vec.x + vec.y * vec.y + vec.z * vec.z);
}
template <typename VALUE>
VALUE dot(const Vec3T<VALUE> &vec1, const Vec3T<VALUE> &vec2)
{
return vec1.x * vec2.x + vec1.y * vec2.y + vec1.z * vec2.z;
}
template <typename VALUE>
Vec3T<VALUE> cross(const Vec3T<VALUE> &vec1, const Vec3T<VALUE> &vec2)
{
return {
vec1.y * vec2.z - vec1.z * vec2.y,
vec1.z * vec2.x - vec1.x * vec2.z,
vec1.x * vec2.y - vec1.y * vec2.x
};
}
template <typename VALUE>
Vec3T<VALUE> normalize(const Vec3T<VALUE> &vec) { return (VALUE)1 / length(vec) * vec; }
// build sample - a tetraeder sponge
template <typename VALUE>
using StoreTriFuncT = std::function<void(const Vec3T<VALUE>&, const Vec3T<VALUE>&, const Vec3T<VALUE>&)>;
namespace TetraSponge {
template <typename VALUE>
void makeTetrix(
const Vec3T<VALUE> &p0, const Vec3T<VALUE> &p1,
const Vec3T<VALUE> &p2, const Vec3T<VALUE> &p3,
StoreTriFuncT<VALUE> &storeTri)
{
storeTri(p0, p1, p2);
storeTri(p0, p2, p3);
storeTri(p0, p3, p1);
storeTri(p1, p3, p2);
}
template <typename VALUE>
void subDivide(
unsigned depth,
const Vec3T<VALUE> &p0, const Vec3T<VALUE> &p1,
const Vec3T<VALUE> &p2, const Vec3T<VALUE> &p3,
StoreTriFuncT<VALUE> &storeTri)
{
if (!depth) { // build the 4 triangles
makeTetrix(p0, p1, p2, p3, storeTri);
} else {
--depth;
auto middle = [](const Vec3T<VALUE> &p0, const Vec3T<VALUE> &p1)
{
return 0.5f * p0 + 0.5f * p1;
};
const Vec3T<VALUE> p01 = middle(p0, p1);
const Vec3T<VALUE> p02 = middle(p0, p2);
const Vec3T<VALUE> p03 = middle(p0, p3);
const Vec3T<VALUE> p12 = middle(p1, p2);
const Vec3T<VALUE> p13 = middle(p1, p3);
const Vec3T<VALUE> p23 = middle(p2, p3);
subDivide(depth, p0, p01, p02, p03, storeTri);
subDivide(depth, p01, p1, p12, p13, storeTri);
subDivide(depth, p02, p12, p2, p23, storeTri);
subDivide(depth, p03, p13, p23, p3, storeTri);
}
}
} // namespace TetraSponge
template <typename VALUE>
void makeTetraSponge(
unsigned depth, // recursion depth (values 0 ... 9 recommended)
StoreTriFuncT<VALUE> &storeTri)
{
TetraSponge::subDivide(depth,
{ -1, -1, -1 },
{ +1, +1, -1 },
{ +1, -1, +1 },
{ -1, +1, +1 },
storeTri);
}
// minimal obj file writer
template <typename VALUE, typename INDEX>
void writeObjFile(
std::ostream &out,
const std::vector<Vec3T<VALUE>> &coords, const std::vector<INDEX> &idcsCoords,
const std::vector<Vec3T<VALUE>> &normals, const std::vector<INDEX> &idcsNormals)
{
assert(idcsCoords.size() == idcsNormals.size());
out
<< "# Wavefront OBJ file\n"
<< "\n"
<< "# " << coords.size() << " coordinates\n";
for (const Vec3 &coord : coords) {
out << "v " << coord.x << " " << coord.y << " " << coord.z << '\n';
}
out
<< "# " << normals.size() << " normals\n";
for (const Vec3 &normal : normals) {
out << "vn " << normal.x << " " << normal.y << " " << normal.z << '\n';
}
out
<< "\n"
<< "g faces\n"
<< "# " << idcsCoords.size() / 3 << " triangles\n";
for (size_t i = 0, n = idcsCoords.size(); i < n; i += 3) {
out << "f "
<< idcsCoords[i + 0] + 1 << "//" << idcsNormals[i + 0] + 1 << ' '
<< idcsCoords[i + 1] + 1 << "//" << idcsNormals[i + 1] + 1 << ' '
<< idcsCoords[i + 2] + 1 << "//" << idcsNormals[i + 2] + 1 << '\n';
}
}
template <typename VALUE, typename INDEX = size_t>
void writeObjFile(
std::ostream &out,
const std::vector<Vec3T<VALUE>> &coords, const std::vector<Vec3T<VALUE>> &normals)
{
assert(coords.size() == normals.size());
std::vector<INDEX> idcsCoords(coords.size());
std::iota(idcsCoords.begin(), idcsCoords.end(), 0);
std::vector<INDEX> idcsNormals(normals.size());
std::iota(idcsNormals.begin(), idcsNormals.end(), 0);
writeObjFile(out, coords, idcsCoords, normals, idcsNormals);
}
// main program (experiment)
template <typename VALUE>
bool operator<(const Vec3T<VALUE> &vec1, const Vec3T<VALUE> &vec2)
{
return vec1.x < vec2.x ? true : vec1.x > vec2.x ? false
: vec1.y < vec2.y ? true : vec1.y > vec2.y ? false
: vec1.z < vec2.z;
}
using Vec3 = Vec3T<float>;
using StoreTriFunc = StoreTriFuncT<float>;
int main(int argc, char **argv)
{
// read command line options
if (argc <= 2) {
std::cerr
<< "Usage:\n"
<< "> testCollectVtcs DEPTH FILE\n";
return 1;
}
const unsigned depth = std::stoi(argv[1]);
const std::string file = argv[2];
std::cout << "Build sample...\n";
std::vector<Vec3> coords, normals;
{ const Time t = stopWatch([&]() {
StoreTriFunc storeTri = [&](const Vec3 &p0, const Vec3 &p1, const Vec3 &p2) {
coords.push_back(p0); coords.push_back(p1); coords.push_back(p2);
const Vec3 n = normalize(cross(p0 - p2, p1 - p2));
normals.push_back(n); normals.push_back(n); normals.push_back(n);
};
makeTetraSponge(depth, storeTri);
});
std::cout << "Done after " << t.count() << " us.\n";
}
std::cout << "coords: " << coords.size() << ", normals: " << normals.size() << '\n';
const std::string fileUncompr = file + ".uncompressed.obj";
std::cout << "Write uncompressed OBJ file '" << fileUncompr << "'...\n";
{ const Time t = stopWatch([&]() {
std::ofstream fOut(fileUncompr.c_str(), std::ios::binary);
/* std::ios::binary -> force Unix line-endings on Windows
* to win some extra bytes
*/
writeObjFile(fOut, coords, normals);
fOut.close();
if (!fOut.good()) {
std::cerr << "Writing of '" << fileUncompr << "' failed!\n";
throw std::ios::failure("Failed to complete writing of file!");
}
});
std::cout << "Done after " << t.count() << " us.\n";
}
std::cout << "Compress coordinates and normals...\n";
std::vector<size_t> idcsCoords, idcsNormals;
{ const Time t = stopWatch([&]() {
idcsCoords = compress(coords);
idcsNormals = compress(normals);
});
std::cout << "Done after " << t.count() << " us.\n";
}
std::cout
<< "coords: " << coords.size() << ", normals: " << normals.size() << '\n'
<< "coord idcs: " << idcsCoords.size() << ", normals: " << normals.size() << '\n';
const std::string fileCompr = file + ".compressed.obj";
std::cout << "Write compressed OBJ file'" << fileCompr << "'...\n";
{ const Time t = stopWatch([&]() {
std::ofstream fOut(fileCompr.c_str(), std::ios::binary);
/* std::ios::binary -> force Unix line-endings on Windows
* to win some extra bytes
*/
writeObjFile(fOut, coords, idcsCoords, normals, idcsNormals);
fOut.close();
if (!fOut.good()) {
std::cerr << "Writing of '" << fileCompr << "' failed!\n";
throw std::ios::failure("Failed to complete writing of file!");
}
});
std::cout << "Done after " << t.count() << " us.\n";
}
std::cout << "Done.\n";
}
A first check:
> testCollectVtcs
Usage:
> testCollectVtcs DEPTH FILE
> testCollectVtcs 1 test1
Build sample...
Done after 34 us.
coords: 48, normals: 48
Write uncompressed OBJ file 'test1.uncompressed.obj'...
Done after 1432 us.
Compress coordinates and normals...
Done after 12 us.
coords: 10, normals: 4
coord idcs: 48, normals: 4
Write compressed OBJ file'test1.compressed.obj'...
Done after 1033 us.
Done.
This produced two files:
$ ls test1.*.obj
-rw-r--r-- 1 Scheff 1049089 553 Mar 26 11:46 test1.compressed.obj
-rw-r--r-- 1 Scheff 1049089 2214 Mar 26 11:46 test1.uncompressed.obj
$
$ cat test1.uncompressed.obj
# Wavefront OBJ file
# 48 coordinates
v -1 -1 -1
v 0 0 -1
v 0 -1 0
v -1 -1 -1
v 0 -1 0
v -1 0 0
v -1 -1 -1
v -1 0 0
v 0 0 -1
v 0 0 -1
v -1 0 0
v 0 -1 0
v 0 0 -1
v 1 1 -1
v 1 0 0
v 0 0 -1
v 1 0 0
v 0 1 0
v 0 0 -1
v 0 1 0
v 1 1 -1
v 1 1 -1
v 0 1 0
v 1 0 0
v 0 -1 0
v 1 0 0
v 1 -1 1
v 0 -1 0
v 1 -1 1
v 0 0 1
v 0 -1 0
v 0 0 1
v 1 0 0
v 1 0 0
v 0 0 1
v 1 -1 1
v -1 0 0
v 0 1 0
v 0 0 1
v -1 0 0
v 0 0 1
v -1 1 1
v -1 0 0
v -1 1 1
v 0 1 0
v 0 1 0
v -1 1 1
v 0 0 1
# 48 normals
vn 0.57735 -0.57735 -0.57735
vn 0.57735 -0.57735 -0.57735
vn 0.57735 -0.57735 -0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 0.57735 -0.57735
vn -0.57735 0.57735 -0.57735
vn -0.57735 0.57735 -0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 -0.57735 -0.57735
vn 0.57735 -0.57735 -0.57735
vn 0.57735 -0.57735 -0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 0.57735 -0.57735
vn -0.57735 0.57735 -0.57735
vn -0.57735 0.57735 -0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 -0.57735 -0.57735
vn 0.57735 -0.57735 -0.57735
vn 0.57735 -0.57735 -0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 0.57735 -0.57735
vn -0.57735 0.57735 -0.57735
vn -0.57735 0.57735 -0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 -0.57735 -0.57735
vn 0.57735 -0.57735 -0.57735
vn 0.57735 -0.57735 -0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 0.57735 -0.57735
vn -0.57735 0.57735 -0.57735
vn -0.57735 0.57735 -0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 0.57735 0.57735
vn 0.57735 0.57735 0.57735
g faces
# 16 triangles
f 1//1 2//2 3//3
f 4//4 5//5 6//6
f 7//7 8//8 9//9
f 10//10 11//11 12//12
f 13//13 14//14 15//15
f 16//16 17//17 18//18
f 19//19 20//20 21//21
f 22//22 23//23 24//24
f 25//25 26//26 27//27
f 28//28 29//29 30//30
f 31//31 32//32 33//33
f 34//34 35//35 36//36
f 37//37 38//38 39//39
f 40//40 41//41 42//42
f 43//43 44//44 45//45
f 46//46 47//47 48//48
$
$ cat test1.compressed.obj
# Wavefront OBJ file
# 10 coordinates
v -1 -1 -1
v 0 0 -1
v 0 -1 0
v -1 0 0
v 1 1 -1
v 1 0 0
v 0 1 0
v 1 -1 1
v 0 0 1
v -1 1 1
# 4 normals
vn 0.57735 -0.57735 -0.57735
vn -0.57735 -0.57735 0.57735
vn -0.57735 0.57735 -0.57735
vn 0.57735 0.57735 0.57735
g faces
# 16 triangles
f 1//1 2//1 3//1
f 1//2 3//2 4//2
f 1//3 4//3 2//3
f 2//4 4//4 3//4
f 2//1 5//1 6//1
f 2//2 6//2 7//2
f 2//3 7//3 5//3
f 5//4 7//4 6//4
f 3//1 6//1 8//1
f 3//2 8//2 9//2
f 3//3 9//3 6//3
f 6//4 9//4 8//4
f 4//1 7//1 9//1
f 4//2 9//2 10//2
f 4//3 10//3 7//3
f 7//4 10//4 9//4
$
So, this what came out
- 48 coordinates vs. 10 coordinates
- 48 normals vs. 4 normals.
And this is, how this looks:
(I couldn't see any visual difference to test1.compressed.obj.)
Concerning the stop-watched times, I wouldn't trust too much them. For this, the sample was much too small.
So, another test with more geometry (much more):
> testCollectVtcs 8 test8
Build sample...
Done after 40298 us.
coords: 786432, normals: 786432
Write uncompressed OBJ file 'test8.uncompressed.obj'...
Done after 6200571 us.
Compress coordinates and normals...
Done after 115817 us.
coords: 131074, normals: 4
coord idcs: 786432, normals: 4
Write compressed OBJ file'test8.compressed.obj'...
Done after 1513216 us.
Done.
>
The two files:
$ ls -l test8.*.obj
-rw-r--r-- 1 ds32737 1049089 11540967 Mar 26 11:56 test8.compressed.obj
-rw-r--r-- 1 ds32737 1049089 57424470 Mar 26 11:56 test8.uncompressed.obj
$
To summarize it:
- 11 MBytes vs. 56 MBytes.
- compressing and writing: 0.12 s + 1.51 s = 1.63 s
- vs. writing the uncompressed: 6.2 s


