This is an interesting question and I was wondering the same when studying Actor Critic Tensorflow implementation.
I guess a main source of confusion may come from the difference between traditional math notation of neural network weights update and its implementation in a programming language. Books and whitepapers often depict this as an update operation towards a model as a whole. While in reality this can be narrowed down to just updating the weights.
In fact this is the only part of the model that needs to be altereted by an optimizer. That's why most optimizers are model agnostic (they don't care which model the weights are from or even if there is a model at all). An optimizer just updates variables using their gradients. And this is what you see in the line 157 of agent.js that you refer to.
However there still is a link to the model in the flow. And it's the loss function. It is used to calculate gradients with tf.variableGrads(lossFunction). And inside the loss function both this.onlineNetwork and this.targetNetwork are used to get the TD error. And here comes the mentioned notation difference: in a book when calculating a TD error (loss) you normally get numerical values. In tfjs case we get gradients as a mapping between a trainable variable and a corresponding gradient value. And this is exactly what optimizer.applyGradients requires as its argument.
You can see this if you debug this DQN example (e.g. in the Chrome Node Inspector).
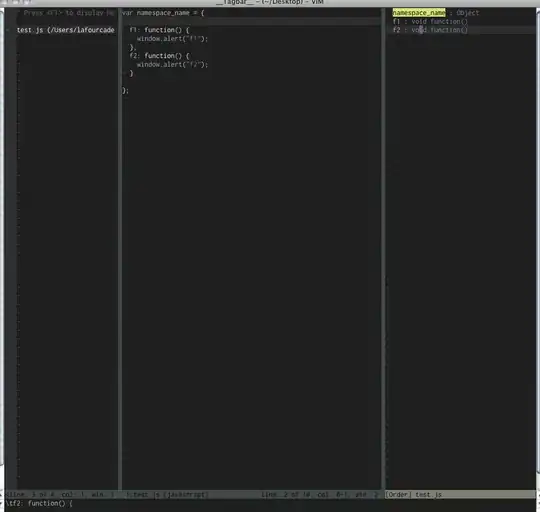
Under the hood the Tensorflow engine has all the trainable variables stored and can handle them by their names. One can see this in the Adam optimizer source code (used for this example).
And if you break just after the gradients are ready (line 166 as shown in the screenshot) you can verify that the optimizer is actually directly dealing with the model weights:
tf.engine().registeredVariables[Object.keys(grads.grads)[0]].dataSync()
and
this.onlineNetwork.getNamedWeights()[0].tensor.dataSync()
will show you the same model weights values.
So a complete chain from the model to the optimizer, if simplified, would look like: this.onlineNetwork > lossFunction > tf.variableGrads > optimizer.applyGradients
And yes, this example uses double DQN to decouple the action selection and learning target calculation.
