library("tidyverse")
library("papaja")
df <- structure(list(investment_type = structure(c(3L, 3L, 3L, 3L,
3L, 3L, 3L, 1L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 1L, 3L, 3L, 3L,
3L), .Label = c("angel", "pre_seed", "seed"), class = "factor"),
gender_d = c(1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1,
1, 1, 1, 1, 0, 1), state_code_org = structure(c(3L, 22L,
3L, 15L, 3L, 4L, 3L, 3L, 22L, 3L, 29L, 25L, 8L, 29L, 10L,
6L, 22L, 4L, 17L, 23L, 17L), .Label = c("AL", "AR", "CA",
"CO", "CT", "DC", "DE", "FL", "GA", "IL", "KS", "LA", "MA",
"MD", "MN", "MO", "NC", "NE", "NH", "NJ", "NV", "NY", "OH",
"OR", "PA", "RI", "SC", "TN", "TX", "UT", "VA", "VT", "WA",
"WI", "WY"), class = "factor"), first_time_founder_d = c(0,
1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, NA, 1, 0, 0, 1,
0)), class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA,
-21L))
df <- df %>%
select(investment_type,
state_code_org,
gender_d,
first_time_founder_d) %>%
mutate_at(c("gender_d", "first_time_founder_d"), list(~ factor(.))) %>%
mutate(gender_d=factor(ifelse(gender_d==1, "Male", "Female"))) %>%
mutate(first_time_founder_d=factor(ifelse(first_time_founder_d==1, "Yes", "No"))) %>%
mutate(investment_type=factor(ifelse(investment_type=="angel", "Angel", ifelse(investment_type=="pre_seed", "Pre-Seed", "Seed")))) %>%
drop_na() %>%
summary() %>%
as.data.frame()
# Clean up columns
df <- df %>%
select(-Var1) %>%
rename(Variable=Var2, N=Freq) %>%
mutate(Variable=factor(ifelse(Variable=="investment_type", "Investment Type", ifelse(Variable=="state_code_org", "State", ifelse(str_detect(Variable, "gender_d"), "Gender", "First-Time Founder"))))) %>%
drop_na()
# break N into level and N
df <- df %>%
separate(col = N, into = c("Level", "N"), sep = ":")
# Remove white space in values
df <- df %>%
mutate(
Variable=trimws(Variable)) %>%
mutate(
Level=trimws(Level)) %>%
mutate(
N=trimws(N))
# Convert N to integer
df <- df %>%
mutate(N=as.integer(N))
df <- df %>%
group_by(Variable) %>%
arrange(Variable, desc(N))
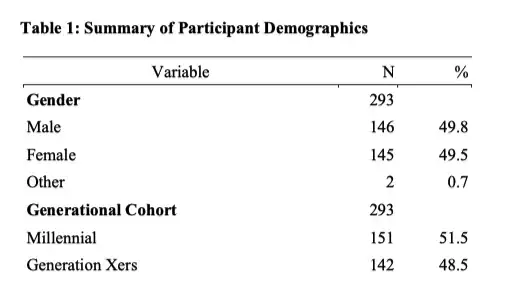
apa_table(
df,
# stub_indents = list("1", "2"),
caption = "Summary of categorical variables.",
note = "Missing data is not shown.")
Here is what I'm getting now.

I am open to using any packages--this happens to use papaja. But it needs to work in rmarkdown with PDF output and comply with APA style.
I would like the table to collapse the Variable values so they are not repeated more than once and also move the State (Other) to the bottom of the state grouping. Something like this (different data set) as an example: