So if I set up the DTS to be on demand, how can I invoke it from an API? I am thinking create a cronjob that calls it on demand every 10 mins. But I can’t figure out through the docs how to call it.
StartManualTransferRuns is part of the RPC library but does not have a REST API equivalent as of now. How to use that will depend on your environment. For instance, you can use the Python Client Library (docs).
As an example, I used the following code (you'll need to run pip install google-cloud-bigquery-datatransfer for the depencencies):
import time
from google.cloud import bigquery_datatransfer_v1
from google.protobuf.timestamp_pb2 import Timestamp
client = bigquery_datatransfer_v1.DataTransferServiceClient()
PROJECT_ID = 'PROJECT_ID'
TRANSFER_CONFIG_ID = '5e6...7bc' # alphanumeric ID you'll find in the UI
parent = client.project_transfer_config_path(PROJECT_ID, TRANSFER_CONFIG_ID)
start_time = bigquery_datatransfer_v1.types.Timestamp(seconds=int(time.time() + 10))
response = client.start_manual_transfer_runs(parent, requested_run_time=start_time)
print(response)
Note that you'll need to use the right Transfer Config ID and the requested_run_time has to be of type bigquery_datatransfer_v1.types.Timestamp (for which there was no example in the docs). I set a start time 10 seconds ahead of the current execution time.
You should get a response such as:
runs {
name: "projects/PROJECT_NUMBER/locations/us/transferConfigs/5e6...7bc/runs/5e5...c04"
destination_dataset_id: "DATASET_NAME"
schedule_time {
seconds: 1579358571
nanos: 922599371
}
...
data_source_id: "google_cloud_storage"
state: PENDING
params {
...
}
run_time {
seconds: 1579358581
}
user_id: 28...65
}
and the transfer is triggered as expected (nevermind the error):
Also, what is my second best most reliable and cheapest way of moving GCS files (no ETL needed) into bq tables that match the exact schema. Should I use Cloud Scheduler, Cloud Functions, DataFlow, Cloud Run etc.
With this you can set a cron job to execute your function every ten minutes. As discussed in the comments, the minimum interval is 60 minutes so it won't pick up files less than one hour old (docs).
Apart from that, this is not a very robust solution and here come into play your follow-up questions. I think these might be too broad to address in a single StackOverflow question but I would say that, for on-demand refresh, Cloud Scheduler + Cloud Functions/Cloud Run can work very well.
Dataflow would be best if you needed ETL but it has a GCS connector that can watch a file pattern (example). With this you would skip the transfer, set the watch interval and the load job triggering frequency to write the files into BigQuery. VM(s) would be running constantly in a streaming pipeline as opposed to the previous approach but a 10-minute watch period is possible.
If you have complex workflows/dependencies, Airflow has recently introduced operators to start manual runs.
If I use Cloud Function, how can I submit all files in my GCS at time of invocation as one bq load job?
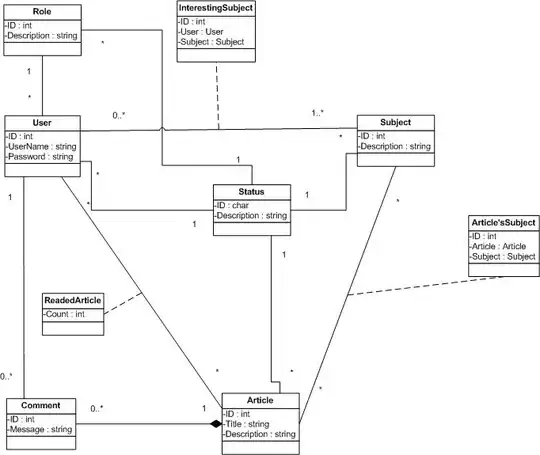
You can use wildcards to match a file pattern when you create the transfer:
Also, this can be done on a file-by-file basis using Pub/Sub notifications for Cloud Storage to trigger a Cloud Function.
Lastly, anyone know if DTS will lower the limit to 10 mins in future?
There is already a Feature Request here. Feel free to star it to show your interest and receive updates


{kind=link}