I have a problem with removing html entities from strings. I try System.Web.HttpUtility.HtmlDecode, and would like to see being replaced with a regular space. Instead, a weird hex code is returned. I have read the following two topics and learned that this is most probably an encoding issue, but I can't find a way to solve it.
Removing HTML entities in strings
How do I remove all HTML tags from a string without knowing which tags are in it? ("I realize that...", Thierry_S)
The source string that should be stripped from html codes and entities is saved in a database with SQL_Latin1_General_CP1_CI_AI as collation, but for my unit test, I simply created a test string in Visual Studio, of which the encoding is not necessarily the same as the encoding of the data that is stored in the database.
My unit test asserts 'Not Equal' since the is not replaced with a regular space. Initially, it returned 2C, but after lots of testing and trying to convert from some encoding to another, it now returns A0 even though I have removed all encoding changing code from my function.
My question is two-fold:
- How can I make my unit test pass?
- Am I testing correctly, since the database encoding could be different from the text I have manually typed in my unit test?
My function:
public static string StripHtml(string text)
{
// Remove html entities like
text = System.Net.WebUtility.HtmlDecode(text);
// Init Html Agility Pack
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(text);
// Return without html tags
return htmlDoc.DocumentNode.InnerText;
}
My unit test:
public void StripHtmlTest()
{
// arrange
string html = "<p>This is a very <b>fat, <i>italic</i> and <u>underlined</u> text,<!-- foo bar --> sigh.</p> And 6 < 9 but > 3.";
string actual;
string expected = "This is a very fat, italic and underlined text, sigh. And 6 < 9 but > 3.";
// act
actual = StaticRepository.StripHtml(html);
// assert
Assert.AreEqual(expected, actual);
}
Test result:
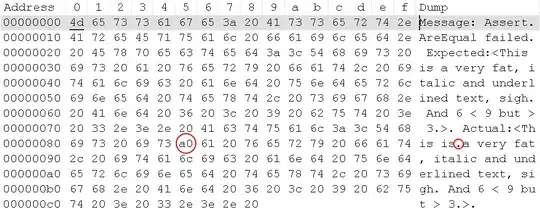
Message: Assert.AreEqual failed. Expected:<This is a very fat, italic and underlined text, sigh. And 6 < 9 but > 3.>. Actual:<This is a very fat, italic and underlined text, sigh. And 6 < 9 but > 3.>.
Test result in HEX: