No way, I'm sorry. You'll need a lot (at least other 1000 images) of non-computer images. You can take them from everywhere, the more they "vary" the better is for your model to extract what features characterize a computer.
Imagine to be a baby that is trained to always say "yes" in front of something, next time you'll se something you'll say "yes" no matter what is in front of you...
The same is for machine learning models, you need positive examples and negative examples, or your model will have 100% accuracy by predicting always "yes".
If you want to see it a mathematically/geometrically, you can see each sample (in your case an image) as a point in the feature space: imagine to draw an axis for each attribute you have (x,y,z an so on), an image will be a point in that space.
For simplicity let's consider a 2-dimension space, which means that each image could be described with 2 attributes (not the case for images, usually the features are a lot, but for simplicity imagine feature_1 = number of colors, feature_2 = number of angles), in this example we can simply draw a point in a cartesian graph, one for each image:
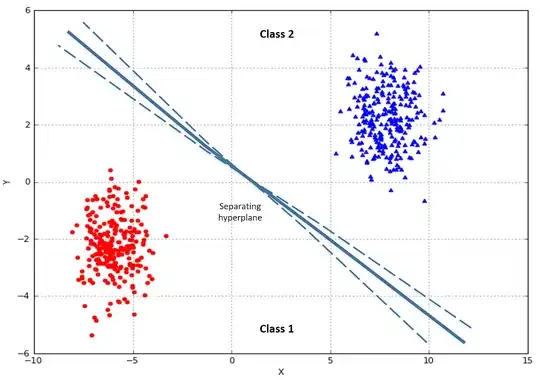
The objective of a classifier is to draw a line which better separate the red dots from the blue dots, which means separate positive examples, from negative examples.
If you give the model only positive samples (which is what you were going to do), you'll have infinite models with 100% accuracy! Because you can put a line wherever you want, the only requirement is to not "cut" your dataset.
Given that I suppose you are a beginner, I'll just tell you what to do, not how because it would take years ;)
1) Collect data - as I told you, even negative examples, at least other 1000 samples
2) Split the data into train/test - a good split could be 2/3 of the samples in the training set and 1/3 in the test set. [REMEMBER] Keep consistency of the final class distribution, i.e. if you had 50%-50% of classes "Computer"-"Non computer", you should keep that percentage for both train set and test set
3) Train a model - have a look at this link for a guided examples, it uses the MNIST dataset, which is a famous image classification one, you should use your data
4) Test the model on the test set and look at performance