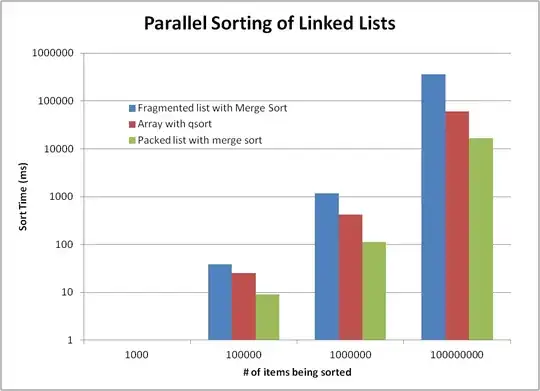
The sigmoid (i.e. logistic) function is scalar, but when described as equivalent to the binary case of the softmax it is interpreted as a 2d function whose arguments ( ) have been pre-scaled by
) have been pre-scaled by  (and hence the first argument is always fixed at 0). The second binary output is calculated post-hoc by subtracting the logistic's output from 1.
(and hence the first argument is always fixed at 0). The second binary output is calculated post-hoc by subtracting the logistic's output from 1.
Since the softmax function is translation invariant,1 this does not affect the output:
The standard logistic function is the special case for a 1-dimensional axis in 2-dimensional space, say the x-axis in the (x, y) plane. One variable is fixed at 0 (say  ), so
), so  , and the other variable can vary, denote it
, and the other variable can vary, denote it  , so
, so
 , the standard logistic function, and
, the standard logistic function, and
 , its complement (meaning they add up to 1).
, its complement (meaning they add up to 1).
Hence, if you wish to use PyTorch's scalar sigmoid as a 2d Softmax function you must manually scale the input ( ), and take the complement for the second output:
), and take the complement for the second output:

# Translate values relative to x0
x_batch_translated = x_batch - x_batch[:,0].unsqueeze(1)
###############################
# The following are equivalent
###############################
# Softmax
torch.softmax(x_batch, dim=1)
# Softmax with translated input
torch.softmax(x_batch_translated, dim=1)
# Sigmoid (and complement) with inputs scaled
torch.stack([1 - torch.sigmoid(x_batch_translated[:,1]),
torch.sigmoid(x_batch_translated[:,1])], dim=1)
tensor([[0.5987, 0.4013],
[0.4013, 0.5987],
[0.8581, 0.1419],
[0.1419, 0.8581]])
tensor([[0.5987, 0.4013],
[0.4013, 0.5987],
[0.8581, 0.1419],
[0.1419, 0.8581]])
tensor([[0.5987, 0.4013],
[0.4013, 0.5987],
[0.8581, 0.1419],
[0.1419, 0.8581]])
-
More generally, softmax is invariant under translation by the same value in each coordinate: adding  to the inputs
to the inputs  yields
yields  , because it multiplies each exponent by the same factor,
, because it multiplies each exponent by the same factor,  (because
(because  ), so the ratios do not change:
), so the ratios do not change: