I'll write some code in Python, because that's what I find the easiest.
I actually wrote both the overlapping and the non-overlapping variants. As a bonus, it also checks that the input is valid.
You seems to be interested only in the overlapping variant:
import itertools
def find_all(
text,
pattern,
overlap=False):
"""
Find all occurrencies of the pattern in the text.
Args:
text (str|bytes|bytearray): The input text.
pattern (str|bytes|bytearray): The pattern to find.
overlap (bool): Detect overlapping patterns.
Yields:
position (int): The position of the next finding.
"""
len_text = len(text)
offset = 1 if overlap else (len(pattern) or 1)
i = 0
while i < len_text:
i = text.find(pattern, i)
if i >= 0:
yield i
i += offset
else:
break
def is_valid(text, tokens):
"""
Check if the text only contains the specified tokens.
Args:
text (str|bytes|bytearray): The input text.
tokens (str|bytes|bytearray): The valid tokens for the text.
Returns:
result (bool): The result of the check.
"""
return set(text).issubset(set(tokens))
def shortest_unique_substr(
text,
tokens='acgt',
overlapping=True,
check_valid_input=True):
"""
Find the shortest unique substring.
Args:
text (str|bytes|bytearray): The input text.
tokens (str|bytes|bytearray): The valid tokens for the text.
overlap (bool)
check_valid_input (bool): Check if the input is valid.
Returns:
result (set): The set of the shortest unique substrings.
"""
def add_if_single_match(
text,
pattern,
result,
overlapping):
match_gen = find_all(text, pattern, overlapping)
try:
next(match_gen) # first match
except StopIteration:
# the pattern is not found, nothing to do
pass
else:
try:
next(match_gen)
except StopIteration:
# the pattern was found only once so add to results
result.add(pattern)
else:
# the pattern is found twice, nothing to do
pass
# just some sanity check
if check_valid_input and not is_valid(text, tokens):
raise ValueError('Input text contains invalid tokens.')
result = set()
# shortest sequence cannot be longer than this
if overlapping:
max_lim = len(text) // 2 + 1
max_lim = len(tokens)
for n in range(1, max_lim + 1):
for pattern_gen in itertools.product(tokens, repeat=2):
pattern = ''.join(pattern_gen)
add_if_single_match(text, pattern, result, overlapping)
if len(result) > 0:
break
else:
max_lim = len(tokens)
for n in range(1, max_lim + 1):
for i in range(len(text) - n):
pattern = text[i:i + n]
add_if_single_match(text, pattern, result, overlapping)
if len(result) > 0:
break
return result
After some sanity check for the correctness of the outputs:
shortest_unique_substr_ovl = functools.partial(shortest_unique_substr, overlapping=True)
shortest_unique_substr_ovl.__name__ = 'shortest_unique_substr_ovl'
shortest_unique_substr_not = functools.partial(shortest_unique_substr, overlapping=False)
shortest_unique_substr_not.__name__ = 'shortest_unique_substr_not'
funcs = shortest_unique_substr_ovl, shortest_unique_substr_not
test_inputs = (
'aaa',
'aaaa',
'aaggcgccttt',
'agggcttttaaaatttaatttgggccc',
)
import functools
for func in funcs:
print('Func:', func.__name__)
for test_input in test_inputs:
print(func(test_input))
print()
Func: shortest_unique_substr_ovl
set()
set()
{'cg', 'ag', 'gg', 'ct', 'aa', 'cc'}
{'tg', 'ag', 'ct'}
Func: shortest_unique_substr_not
{'aa'}
{'aaa'}
{'cg', 'tt', 'ag', 'gg', 'ct', 'aa', 'cc'}
{'tg', 'ag', 'ct', 'cc'}
it is wise to benchmark how fast we actually are.
Below you can find some benchmarks, produced using some template code from here (the overlapping variant is in blue):
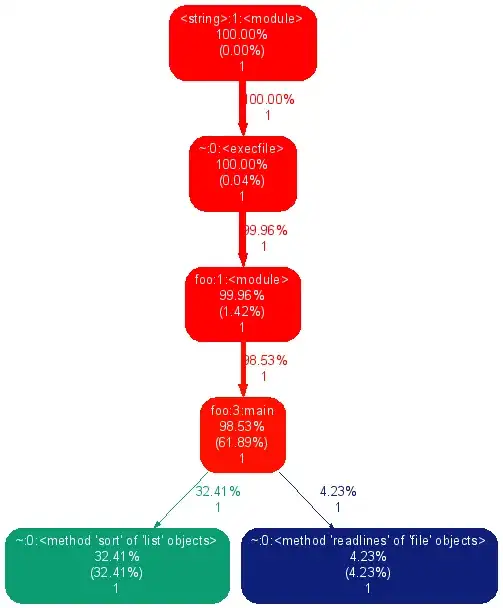
and the rest of the code for completeness:
def gen_input(n, tokens='acgt'):
return ''.join([tokens[random.randint(0, len(tokens) - 1)] for _ in range(n)])
def equal_output(a, b):
return a == b
input_sizes = tuple(2 ** (1 + i) for i in range(16))
runtimes, input_sizes, labels, results = benchmark(
funcs, gen_input=gen_input, equal_output=equal_output,
input_sizes=input_sizes)
plot_benchmarks(runtimes, input_sizes, labels, units='ms')
plot_benchmarks(runtimes, input_sizes, labels, units='μs', zoom_fastest=2)
As far as the asymptotic time-complexity analysis is concerned, considering only the overlapping case, let N be the input size, let K be the number of tokens (4 in your case), find_all() is O(N), and the body of shortest_unique_substr is O(K²) (+ O((K - 1)²) + O((K - 2)²) + ...).
So, this is overall O(N*K²) or O(N*(Σk²)) (for k = 1, …, K), since K is fixed, this is O(N), as the benchmarks seem to indicate.

