I have a dataset which includes over 100 countries in it. I want to include these in an XGBoost model to make a classification prediction. I know that One Hot Encoding is the go-to process for this, but I would rather do something that wont increase the dimensionality so much and will be resilient to new values, so I'm trying binary classification using the category_encoders package. http://contrib.scikit-learn.org/categorical-encoding/binary.html
Using this encoding helped my model out over using basic one-hot encoding, but how do I get back to the original labels after encoding?
I know about the inverse_transform method, but that functions on the whole data frame. I need a way where I can put in a binary, or integer value and get back the original value.
Here's some example data taken from: https://towardsdatascience.com/smarter-ways-to-encode-categorical-data-for-machine-learning-part-1-of-3-6dca2f71b159
import numpy as np
import pandas as pd
import category_encoders as ce
# make some data
df = pd.DataFrame({
'color':["a", "c", "a", "a", "b", "b"],
'outcome':[1, 2, 3, 2, 2, 2]})
# split into X and y
X = df.drop('outcome', axis = 1)
y = df.drop('color', axis = 1)
# instantiate an encoder - here we use Binary()
ce_binary = ce.BinaryEncoder(cols = ['color'])
# fit and transform and presto, you've got encoded data
ce_binary.fit_transform(X, y)
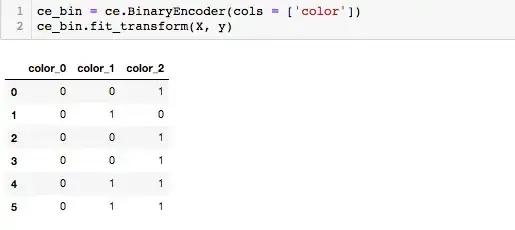
I'd like to pass the values [0,0,1] or 1 into a function and get back a as a value.
The main reason for this is for looking at the feature importances of the model. I can get feature importances based on a column, but this will give me back a column id rather than the underlying value of a category that is the most important.