What you want to maximize is
J(theta) = int( p(tau;theta)*R(tau) )
The integral is over tau (the trajectory) and p(tau;theta) is its probability (i.e., of seeing the sequence state, action, next state, next action, ...), which depends on both the dynamics of the environment and the policy (parameterized by theta). Formally
p(tau;theta) = p(s_0)*pi(a_0|s_0;theta)*P(s_1|s_0,a_0)*pi(a_1|s_1;theta)*P(s_2|s_1,a_1)*...
where P(s'|s,a) is the transition probability given by the dynamics.
Since we cannot control the dynamics, only the policy, we optimize w.r.t. its parameters, and we do it by gradient ascent, meaning that we take the direction given by the gradient. The equation in your image comes from the log-trick df(x)/dx = f(x)*d(logf(x))/dx.
In our case f(x) is p(tau;theta) and we get your equation. Then since we have access only to a finite amount of data (our samples) we approximate the integral with an expectation.
Step after step, you will (ideally) reach a point where the gradient is 0, meaning that you reached a (local) optimum.
You can find a more detailed explanation here.
EDIT
Informally, you can think of learning the policy which increases the probability of seeing high return R(tau). Usually, R(tau) is the cumulative sum of the rewards. For each state-action pair (s,a) you therefore maximize the sum of the rewards you get from executing a in state s and following pi afterwards. Check this great summary for more details (Fig 1).
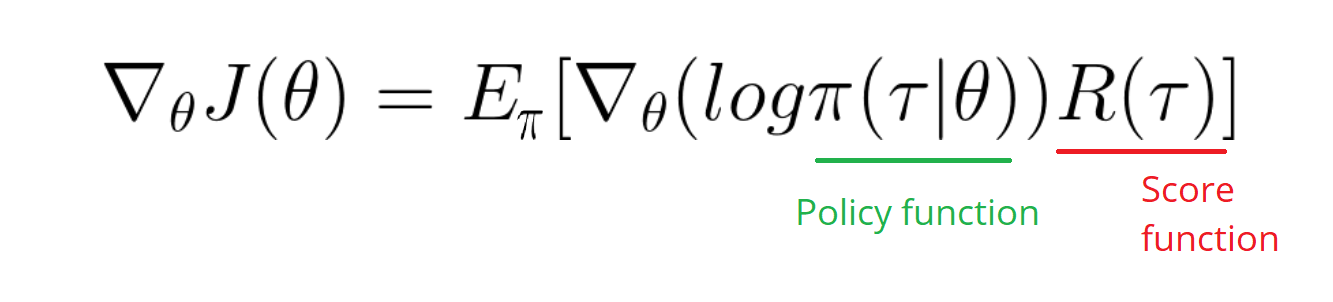{kind=link}