I've built a simple CNN word detector that is accurately able to predict a given word when using a 1-second .wav as input. As seems to be the standard, I'm using the MFCC of the audio files as input for the CNN.
However, my goal is to be able to apply this to longer audio files with multiple words being spoken, and to have the model be able to predict if and when a given word is spoken. I've been searching online how the best approach, but seem to be hitting a wall and I truly apologize if the answer could've been easily found through google.
My first thought is to cut the audio file into several windows of 1-second length that intersect each other -
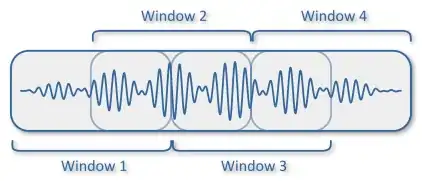
and then convert each window into an MFCC and use these as input for the model prediction.
My second thought would be to instead use onset detection in attempts isolate each word, add padding if the word if it was < 1-second, and then feed these as input for the model prediction.
Am I way off here? Any references or recommendations would hugely appreciated. Thank you.