Let’s assume simplified example as below
Table1
Mappingtable

The way I would approach your use case manually would be as below
First, assume we know in advance all mappings and we can assemble needed list manually and use it as below
#standardSQL
CREATE OR REPLACE TABLE `project.dataset.Table1` AS
SELECT NULL AS Role_number, NULL AS Person_name -- this line to be generated
FROM (SELECT 1) WHERE FALSE UNION ALL
SELECT * FROM `project.dataset.Table1`
Now, we need to “figure out” how to generate below line from the above query
'SELECT NULL AS Role_number, NULL AS Person_name'
This can be done by running below query
#standardSQL
SELECT CONCAT('SELECT', STRING_AGG(CONCAT(' NULL AS ', RealColumnName) ORDER BY pos)) select_statement
FROM (
SELECT TO_JSON_STRING(t) AS cols FROM `project.dataset.Table1` t LIMIT 1
), UNNEST(REGEXP_EXTRACT_ALL(cols, r'"(.*?)":')) col WITH OFFSET AS pos
LEFT JOIN `project.dataset.Mappingtable` ON tempColumnName = col
This will produce exactly string we need
'SELECT NULL AS Role_number, NULL AS Person_name'
So, now the question is how to add above dynamically built fragment into query that we are interested in!
Unfortunately, it is not doable as a one query purely within the BigQuery, but super simple task to accomplish in ANY client or tool of your choice
I can demonstrate how easily this can be done by non-technical user with the Tool of my choice – Magnus (part of Potens.io – Suite of tools for BigQuery)
Below is snapshot of Magnus Workflow with just two BigQuery Tasks, which reproduce exactly above steps
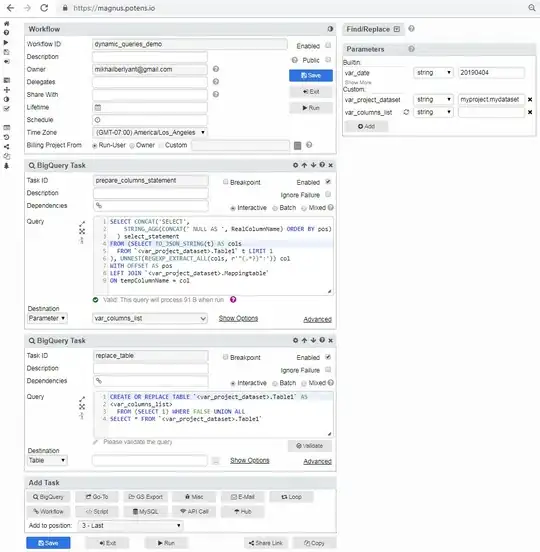
As you can see here:
In first Task we generate the statement with expected mapped Column names and assign result to parameter called var_columns_list (after workflow execution it will get expected value)

In second Task we just simply building dynamic sql using that parameter
Also, you can notice that instead of using plain reference to tables like project.dataset.Table1 and project.dataset.Mappingtable - I am using <var_project_dataset>.Table1 and <var_project_dataset>.Mappingtable and parameter var_project_dataset is set in parameters panel
After running that workflow ,we get expected result as shown below

While before execution it was

Obviously this is simplified example and it will work AS IS only if you have basic column types - no structs and no arrays. Still good news is this approach will easily handle 200 or even more columns you mentioned in your question.
Anyway, I think above example can be a good start for you!
Disclosure: I am an author and leader of Potens.io Team which is reflected in my profile. I am also Google Developer Expert for Cloud Platform and author of BigQuery Mate Chrome Extension





