I'm working on the project for my graduation in college. I already did one pipelined CPU and simulated it in Logisim program for one of my courses, but now I need to flash CPU to my FPGA and write game for this CPU also. So I thought to improve my architecture and also I altered some functions, because didn't really knew how it should work. The problem is with Memory accessing, on the first picture you can see my first CPU. Logic was: Read opcode->decode and prepare operands->Read memory if needed->Check if JMP(CJE,CJNE...)->Arithmetic and logic calculations->Write answer to register or to memory (I delayed here for 1 clock all pipeline if needed for not to collide with read memory operations - Memory Hazard avoiding).
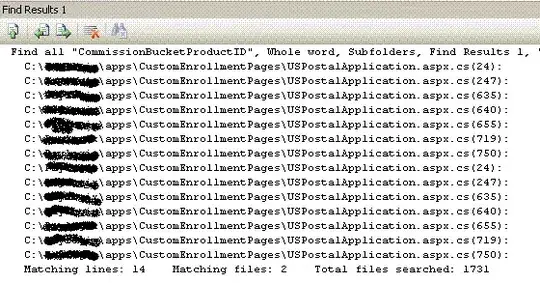
Now I want to insert some graphics for my game and added one more segment that will cooperate with PPU(Picture Processing Unit).
Also, I saw a lot of examples in the Internet that put Memory segment after Execution segment and that is not understandable for me. How I can implement opcode like ADD A, MEM if I need to read the MEM variable form Memory and then to add it to A? Or I'm missing something? Can you, please, help me with that?