@Srikar Appalaraju is right. Take the following example image:
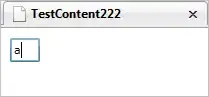
Now use the following code:
text = pytesseract.image_to_data(gray, output_type='data.frame')
text = text[text.conf != -1]
text.head()
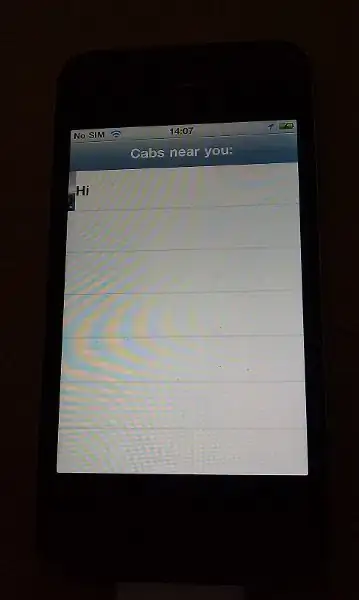
Notice that all five rows have the same block_num, so that if we group by using that column, all the 5 words (texts) will be grouped together. But that's not what we want, we want to group only the first 3 words that belong to the first line and in order to do that properly (in a generic manner) for a large enough image we need to group by all the 4 columns page_num, block_num, par_num and line_num simulataneuosly, in order to compute the confidence for the first line, as shown in the following code snippet:
lines = text.groupby(['page_num', 'block_num', 'par_num', 'line_num'])['text'] \
.apply(lambda x: ' '.join(list(x))).tolist()
confs = text.groupby(['page_num', 'block_num', 'par_num', 'line_num'])['conf'].mean().tolist()
line_conf = []
for i in range(len(lines)):
if lines[i].strip():
line_conf.append((lines[i], round(confs[i],3)))
with the following desired output:
[('Ying Thai Kitchen', 91.667),
('2220 Queen Anne AVE N', 88.2),
('Seattle WA 98109', 90.333),
('« (206) 285-8424 Fax. (206) 285-8427', 83.167),
('‘uw .yingthaikitchen.com', 40.0),
('Welcome to Ying Thai Kitchen Restaurant,', 85.333),
('Order#:17 Table 2', 94.0),
('Date: 7/4/2013 7:28 PM', 86.25),
('Server: Jack (1.4)', 83.0),
('44 Ginger Lover $9.50', 89.0),
('[Pork] [24#]', 43.0),
('Brown Rice $2.00', 95.333),
('Total 2 iten(s) $11.50', 89.5),
('Sales Tax $1.09', 95.667),
('Grand Total $12.59', 95.0),
('Tip Guide', 95.0),
('TEK=$1.89, 18%=62.27, 20%=82.52', 6.667),
('Thank you very much,', 90.75),
('Cone back again', 92.667)]

