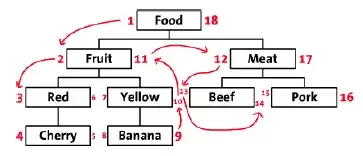
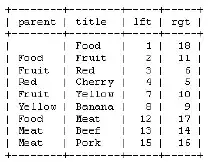
Thinking out loud here, but perhaps it would be helpful to view some attributes (like Red, Yellow and Green) as 'tags' instead of 'categories' and handle them with separate logic. That would let you keep the Nested Set model and avoid unnecessary duplication. Plus, it would allow you to keep your categories simpler.
It's all in how you think about the information. Categories are just another way of representing attributes. I understand your example was just for illustrative purposes, but if you're going to categorize fruit by color, why would you not also categorize meat the same way, i.e., white meat and red meat? Most likely you would not. So my point is it's probably not necessary to categorize fruit by color, either.
Instead, some attributes are better represented in other ways. In fact, in its simplest form, it could be recorded as a column in the 'food' table labeled 'color'. Or, if it's a very common attribute and you find yourself duplicating the value significantly, it could be split off to a separate table named 'color' and mapped to each food item from a third table. Of course, the more abstract approach would be to generalize the table as 'tags' and include each color as an individual tag that can then be mapped to any food item. Then you can map any number of tags (colors) to any number of food items, giving you a true many-to-many relationship and freeing up your category designations to be more generalized as well.
I know there's ongoing debate about whether tags are categories or categories are tags, etc., but this appears to be one instance in which they could be complimentary and create a more abstract and robust system that's easier to manage.