I've compared the suggested solutions with perfplot and found that
len(lst) == len(set(lst))
is indeed the fastest solution. If there are early duplicates in the list, there are some constant-time solutions which are to be preferred.
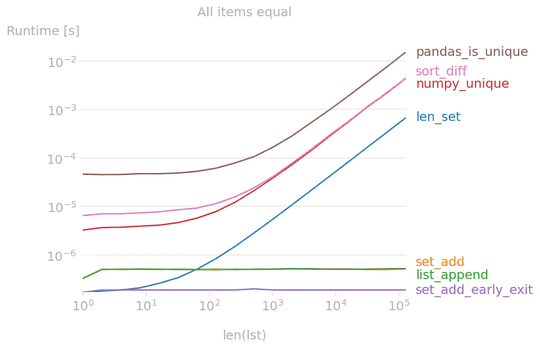
Code to reproduce the plot:
import perfplot
import numpy as np
import pandas as pd
def len_set(lst):
return len(lst) == len(set(lst))
def set_add(lst):
seen = set()
return not any(i in seen or seen.add(i) for i in lst)
def list_append(lst):
seen = list()
return not any(i in seen or seen.append(i) for i in lst)
def numpy_unique(lst):
return np.unique(lst).size == len(lst)
def set_add_early_exit(lst):
s = set()
for item in lst:
if item in s:
return False
s.add(item)
return True
def pandas_is_unique(lst):
return pd.Series(lst).is_unique
def sort_diff(lst):
return not np.any(np.diff(np.sort(lst)) == 0)
b = perfplot.bench(
setup=lambda n: list(np.arange(n)),
title="All items unique",
# setup=lambda n: [0] * n,
# title="All items equal",
kernels=[
len_set,
set_add,
list_append,
numpy_unique,
set_add_early_exit,
pandas_is_unique,
sort_diff,
],
n_range=[2**k for k in range(18)],
xlabel="len(lst)",
)
b.save("out.png")
b.show()

