I am trying to create a reinforcement learning agent that can buy, sell or hold stock positions. The issue I'm having is that even after over 2000 episodes, the agent still can not learn when to buy, sell or hold. Here is an image from the 2100th episode detailing what I mean, the agent will not take any action unless it is random.
 The agent learns using a replay memory and I have double and triple checked that there are no errors. Here is the code for the agent:
import numpy as np
import tensorflow as tf
import random
from collections import deque
from .agent import Agent
The agent learns using a replay memory and I have double and triple checked that there are no errors. Here is the code for the agent:
import numpy as np
import tensorflow as tf
import random
from collections import deque
from .agent import Agent
class Agent(Agent):
def __init__(self, state_size = 7, window_size = 1, action_size = 3,
batch_size = 32, gamma=.95, epsilon=.95, epsilon_decay=.95, epsilon_min=.01,
learning_rate=.001, is_eval=False, model_name="", stock_name="", episode=1):
"""
state_size: Size of the state coming from the environment
action_size: How many decisions the algo will make in the end
gamma: Decay rate to discount future reward
epsilon: Rate of randomly decided action
epsilon_decay: Rate of decrease in epsilon
epsilon_min: The lowest epsilon can get (limit to the randomness)
learning_rate: Progress of neural net in each iteration
episodes: How many times data will be run through
"""
self.state_size = state_size
self.window_size = window_size
self.action_size = action_size
self.batch_size = batch_size
self.gamma = gamma
self.epsilon = epsilon
self.epsilon_decay = epsilon_decay
self.epsilon_min = epsilon_min
self.learning_rate = learning_rate
self.is_eval = is_eval
self.model_name = model_name
self.stock_name = stock_name
self.q_values = []
self.layers = [150, 150, 150]
tf.reset_default_graph()
self.sess = tf.Session(config=tf.ConfigProto(allow_soft_placement = True))
self.memory = deque()
if self.is_eval:
model_name = stock_name + "-" + str(episode)
self._model_init()
# "models/{}/{}/{}".format(stock_name, model_name, model_name + "-" + str(episode) + ".meta")
self.saver = tf.train.Saver()
self.saver.restore(self.sess, tf.train.latest_checkpoint("models/{}/{}".format(stock_name, model_name)))
# self.graph = tf.get_default_graph()
# names=[tensor.name for tensor in tf.get_default_graph().as_graph_def().node]
# self.X_input = self.graph.get_tensor_by_name("Inputs/Inputs:0")
# self.logits = self.graph.get_tensor_by_name("Output/Add:0")
else:
self._model_init()
self.sess.run(self.init)
self.saver = tf.train.Saver()
path = "models/{}/6".format(self.stock_name)
self.writer = tf.summary.FileWriter(path)
self.writer.add_graph(self.sess.graph)
def _model_init(self):
"""
Init tensorflow graph vars
"""
# (1,10,9)
with tf.device("/device:GPU:0"):
with tf.name_scope("Inputs"):
self.X_input = tf.placeholder(tf.float32, [None, self.state_size], name="Inputs")
self.Y_input = tf.placeholder(tf.float32, [None, self.action_size], name="Actions")
self.rewards = tf.placeholder(tf.float32, [None, ], name="Rewards")
# self.lstm_cells = [tf.contrib.rnn.GRUCell(num_units=layer)
# for layer in self.layers]
#lstm_cell = tf.contrib.rnn.LSTMCell(num_units=n_neurons, use_peepholes=True)
#gru_cell = tf.contrib.rnn.GRUCell(num_units=n_neurons)
# self.multi_cell = tf.contrib.rnn.MultiRNNCell(self.lstm_cells)
# self.outputs, self.states = tf.nn.dynamic_rnn(self.multi_cell, self.X_input, dtype=tf.float32)
# self.top_layer_h_state = self.states[-1]
# with tf.name_scope("Output"):
# self.out_weights=tf.Variable(tf.truncated_normal([self.layers[-1], self.action_size]))
# self.out_bias=tf.Variable(tf.zeros([self.action_size]))
# self.logits = tf.add(tf.matmul(self.top_layer_h_state,self.out_weights), self.out_bias)
fc1 = tf.contrib.layers.fully_connected(self.X_input, 512, activation_fn=tf.nn.relu)
fc2 = tf.contrib.layers.fully_connected(fc1, 512, activation_fn=tf.nn.relu)
fc3 = tf.contrib.layers.fully_connected(fc2, 512, activation_fn=tf.nn.relu)
fc4 = tf.contrib.layers.fully_connected(fc3, 512, activation_fn=tf.nn.relu)
self.logits = tf.contrib.layers.fully_connected(fc4, self.action_size, activation_fn=None)
with tf.name_scope("Cross_Entropy"):
self.loss_op = tf.losses.mean_squared_error(self.Y_input,self.logits)
self.optimizer = tf.train.RMSPropOptimizer(learning_rate=self.learning_rate)
self.train_op = self.optimizer.minimize(self.loss_op)
# self.correct = tf.nn.in_top_k(self.logits, self.Y_input, 1)
# self.accuracy = tf.reduce_mean(tf.cast(self., tf.float32))
tf.summary.scalar("Reward", tf.reduce_mean(self.rewards))
tf.summary.scalar("MSE", self.loss_op)
# Merge all of the summaries
self.summ = tf.summary.merge_all()
self.init = tf.global_variables_initializer()
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon and not self.is_eval:
prediction = random.randrange(self.action_size)
if prediction == 1 or prediction == 2:
print("Random")
return prediction
act_values = self.sess.run(self.logits, feed_dict={self.X_input: state.reshape((1, self.state_size))})
if np.argmax(act_values[0]) == 1 or np.argmax(act_values[0]) == 2:
pass
return np.argmax(act_values[0])
def replay(self, time, episode):
print("Replaying")
mini_batch = []
l = len(self.memory)
for i in range(l - self.batch_size + 1, l):
mini_batch.append(self.memory[i])
mean_reward = []
x = np.zeros((self.batch_size, self.state_size))
y = np.zeros((self.batch_size, self.action_size))
for i, (state, action, reward, next_state, done) in enumerate(mini_batch):
target = reward
if not done:
self.target = reward + self.gamma * np.amax(self.sess.run(self.logits, feed_dict = {self.X_input: next_state.reshape((1, self.state_size))})[0])
current_q = (self.sess.run(self.logits, feed_dict={self.X_input: state.reshape((1, self.state_size))}))
current_q[0][action] = self.target
x[i] = state
y[i] = current_q.reshape((self.action_size))
mean_reward.append(self.target)
#target_f = np.array(target_f).reshape(self.batch_size - 1, self.action_size)
#target_state = np.array(target_state).reshape(self.batch_size - 1, self.window_size, self.state_size)
_, c, s = self.sess.run([self.train_op, self.loss_op, self.summ], feed_dict={self.X_input: x, self.Y_input: y, self.rewards: mean_reward}) # Add self.summ into the sess.run for tensorboard
self.writer.add_summary(s, global_step=(episode+1)/(time+1))
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
Once the replay memory is greater than the batch size, it runs the replay function. The code might look a little messy since I have been messing with it for days now trying to figure this out. Here is a screenshot of the MSE from tensorboard.
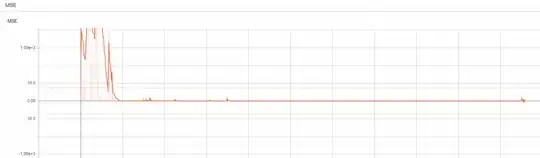 As you can see by the 200th episode the MSE dies out to 0 or almost 0. I'm stumped! I have no idea what is going on. Please help me figure this out. The code is posted here to see the whole thing including the train and eval files. The main agent I have been working on is LSTM.py in tha agents folder. Thanks!
As you can see by the 200th episode the MSE dies out to 0 or almost 0. I'm stumped! I have no idea what is going on. Please help me figure this out. The code is posted here to see the whole thing including the train and eval files. The main agent I have been working on is LSTM.py in tha agents folder. Thanks!