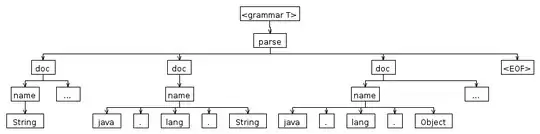
I'm trying to parse the following grammar with Antlr3:
String...
java.lang.String
java.lang.Object...
This is my .g file (part of it):
doc: name DOTS? EOF;
name: ATOM ('.' ATOM)*;
ATOM: ('a' .. 'z' | 'A' .. 'Z')+;
DOTS: '...';
It doesn't work. Antlr3 treats '.' after ATOM as part of name, not the beginning of DOTS. How can I solve it?