the source code of the corresponding image is shown below
why a paragraph like this can be displayed as an image like that
It's not though. That paragraph is not the source code of the image and it's not displayed as an image. The site you linked has the image & the paragraph of text, side by side & "independent" of each-other.
I.e. the image is just an image (& accessable via its direct url: https://www.sec.gov/Archives/edgar/data/104169/000167276417000039/p55218x61x1.jpg):

And the paragraph of text is just a paragraph of text:
<p style="font: 1pt Arial, Helvetica, Sans-Serif; margin: 0pt 0; color: White">
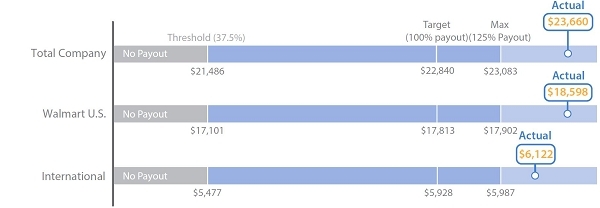
Total Company Threshold (37.5%) Target (100% payout) Max (125% Payout) Actual $23,660 No Payout $21,486 $22,840 $23,083 Walmart U.S. No Payout $17,101 $17,813 $17,902 International No Payout $5,477 $5,928 $5,987 Adjusted Constant Currency Sales (excluding fuel)* Total Company No Payout Actual $483,559 $473,456 $483,384 $485,855 Actual $306,287 Walmart U.S. No Payout $300,526 $306,346 $307,878 Actual $121,590 International No Payout $118,702 $120,962 $121,566
</p>
One does not create another in this case.
Note how the paragraph with the information you need has the font style set to be 1pt and to be colored White (on an already white background). Basically the text is there but it's made invisible to the human eye. There isn't an easy way to read texts out of images so the likely reason that paragraph is there at all is so that the information on that web-page could be indexed by search engines (if it only consisted of imaged without paragraphs of texts like that - search engines would have a hard time understanding what was going on on that page). Though there could be other reasons as well (like it was a pdf file initially converted into an HTML page by a software that left that paragraph there for whatever reasons whether on purpose or not).
Now, while it's actually good that they have the text versions of the data - unfortunately the way it's structured (pretty much no structure at all, just appended data) makes it difficult to parse the end result and though it would still be possible - there's no reason to do that as if you look around at other parts of that report (for example on page 64) - you'll see that there's a text version of that same data in a nicely formatted table which would be a lot easier to parse and the image you initially pointed at was likely generated from the table here.
If that doesn't help and you still need the data from images which can't be found as text in the source of that page & since the page itself looks like it was automatically generated by a software from something else - you'd likely have better luck finding the original source of that data, if at all possible.