I am trying to write simple spark dataframe to db2 database using pySpark. Dataframe has only one column with double as a data type.
This is the dataframe with only one row and one column:
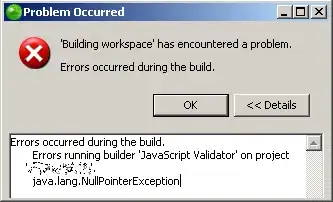
This is the dataframe schema:

When I try to write this dataframe to db2 table with this syntax:
dataframe.write.mode('overwrite').jdbc(url=url, table=source, properties=prop)
it creates the table in the database for the first time without any issue, but if I run the code second time, it throws an exception:
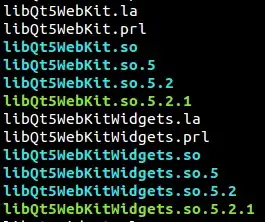
On the DB2 side the column datatype is also DOUBLE.
Not sure what am I missing.