The technique you are addressing is called "Transfer Learning" - when a pre-trained model on a different dataset is used as part of the model as a starting point for better convergence. The intuition behind it is simple: we assume that after training on such a large and rich dataset as ImageNet, the convolution kernels of the model will learn useful representations.
In your specific case, you want to stack VGG16 weights in the bottom and deconvolution blocks on the top. I will go step-by-step, as you pointed out that you are new to Keras. This answer is organized as a step-by-step tutorial and will provide small snippets for you to use in your own code.
Loading weights
In the PyTorch code you linked to above, the model was first defined, and only then the weights are copied. I found this approach abundant, as it contains lots of not necessary code. Here, we will load VGG16 first, and then stack the other layers on the top.
from keras import applications
from keras.layers import Input
# Loading without top layers, since you only need convolution. Note that by not
# specifying the shape of top layers, the input tensor shape is (None, None, 3),
# so you can use them for any size of images.
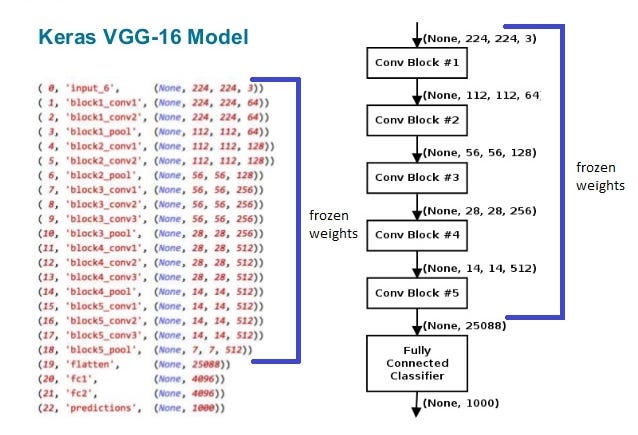
vgg_model = applications.VGG16(weights='imagenet', include_top=False)
# If you want to specify input tensor shape, e.g. 256x256 with 3 channels:
input_tensor = Input(shape=(256, 256, 3))
vgg_model = applications.VGG16(weights='imagenet',
include_top=False,
input_tensor=input_tensor)
# To see the models' architecture and layer names, run the following
vgg_model.summary()
Defining the U-Net computation graph with VGG16 on the bottom
As pointed in previous paragraph, you do not need to define a model and copy the weights over. Just stack other layers on top of vgg_model:
# Import the layers to be used in U-Net
from keras.layers import ...
# From the U-Net code you provided
def make_conv_block(nb_filters, input_tensor, block):
...
# Creating dictionary that maps layer names to the layers
layers = dict([(layer.name, layer) for layer in vgg_model.layers])
# Getting output tensor of the last VGG layer that we want to include.
# I don't know much about U-Net, but according to the code you provided,
# you don't need the last pooling layer, right?
vgg_top = layers['block5_conv3'].output
# Now getting bottom layers for multi-scale skip-layers
block1_conv2 = layers['block1_conv2'].output
block2_conv2 = layers['block2_conv2'].output
block3_conv3 = layers['block3_conv3'].output
block4_conv3 = layers['block4_conv3'].output
# Stacking the remaining layers of U-Net on top of it (modified from
# the U-Net code you provided)
up6 = Concatenate()([UpSampling2D(size=(2, 2))(vgg_top), block4_conv3])
conv6 = make_conv_block(256, up6, 6)
up7 = Concatenate()([UpSampling2D(size=(2, 2))(conv6), block3_conv3])
conv7 = make_conv_block(128, up7, 7)
up8 = Concatenate()([UpSampling2D(size=(2, 2))(conv7), block2_conv2])
conv8 = make_conv_block(64, up8, 8)
up9 = Concatenate()([UpSampling2D(size=(2, 2))(conv8), block1_conv2])
conv9 = make_conv_block(32, up9, 9)
conv10 = Conv2D(nb_labels, (1, 1), name='conv_10_1')(conv9)
x = Reshape((nb_rows * nb_cols, nb_labels))(conv10)
x = Activation('softmax')(x)
outputs = Reshape((nb_rows, nb_cols, nb_labels))(x)
I want to emphasize that what we've done in this paragraph is just defining the computation graph for U-Net. This code is written specifically for VGG16, but you can modify it for other architectures as you wish.
Creating a model
After the previous step, we've got a computational graph (I assume that you use Tensorflow backend for Keras. If you're using Theano, I recommend you to switch to Tensorflow since this framework has achieved a state of maturity now). Now, we need to do the following things:
- Create a model on top of this computation graph
- Freeze the bottom layers, since you don't want to wreck your pre-trained weights
# Creating new model. Please note that this is NOT a Sequential() model
# as in commonly found tutorials on the internet.
from keras.models import Model
custom_model = Model(inputs=vgg_model.input, outputs=outputs)
# Make sure that the pre-trained bottom layers are not trainable.
# Here, I freeze all the layers of VGG16 (layers 0-18, including the
# pooling ones.
for layer in custom_model.layers[:19]:
layer.trainable = False
# Do not forget to compile it before training
custom_model.compile(loss='your_loss',
optimizer='your_optimizer',
metrics=['your_metrics'])
"I got confused"
Assuming that you're new to Keras and to Deep Learning in general (as you admitted in your question), I recommend the following articles to read to further understand the process of Fine Tuning and Transfer Learning on Keras:
When you're learning a framework, documentation is your best friend. Fortunately, Keras has an incredible documentation.
Q&A
The deconvolution blocks we put on top of VGG are from the UNET achitecture (i.e. up6 to conv10)? Please confirm.
Yes, it's the same as here, just with different names of the skip-connection layers (e.g. block1_conv2 instead of conv1)
We leave out the conv layers (i.e., conv1 to conv5). Can you please share with me as to why this is so?
We don't leave or throw any layers from the VGG network. The VGG16 network architecture and the bottom architecture of U-Net (up to conv5) is very similar. In fact, they are made of 5 blocks of the following format:
+-----------------+-------------------+
| VGG conv blocks | U-Net conv blocks |
+-----------------+-------------------+
| blockX_conv1 | convN |
| ... | poolN |
| blockX_convN | |
| blockX_pool | |
+-----------------+-------------------+
Here is a better visualization. So, the only difference between VGG16 and bottom part of U-Net is that each block of VGG16 contains multiple convolution layers instead of one. That's why, the alternative of connecting conv3 to conv6 is connecting block3_conv3 to conv6. The U-Net architecture remains the same, just with more convolution layers on the bottom.
Is there anyway to incorporate the Max pooling in the conv layers (in your opinion what are we doing here by leaving them out, and would you say it is insignificant?)
We don't leave them out. The only pooling layer that I threw away is block5_pool (which is the last layer in bottom part of VGG16) - because in the original U-Net (refer to the code) it seems like the last convolution block in the bottom part is not followed by a pooling layer (we have conv5 but don't have pool5). I kept all the layers of VGG16.
We see Maxpooling being used on the convolution blocks. Would we also just simply drop these pooling layers (as we are doing here with Unet) if we wanted to combine Segnet with VGG?
As I explained in the question above, we are not dropping any pooling layers.
However, you would need to stack a different type of pooling layers instead of the simple MaxPooling2D that is used in the default VGG16, because SegNet preserves max-indexes. This can be achieved with tf.nn.max_pool_with_argmax and using the trick of replacing middle layers of Keras model (I won't cover the detailed information in this answer to keep it clean). The replacement is harmless and doesn't require re-training because pooling layers don't contain any trained weights.
The U-NET from here is different from what I am using, can you tell what is the impact of such a difference between the two?
It is a more shallow U-Net. The one in your original question has 5 convolution blocks on the bottom (conv1 - conv5), while the later only has 3. Choose how many blocks you need depending on the data (e.g. for simple data as cells you might want to use only 2-3 blocks, while gray matter or tissue segmentation might require 5 blocks for better quality. See this link to have an insight of what convolution kernels "see".
Also, what do you think about the VGGSegnet from here. Does it use the trick of the middle layers you mentioned in Q&A? And is it the equivalent of the Pytorch code I initially posted?
Interesting. It is an incorrect implementation, and is not equivalent to the Pytorch code you posted. I have opened an issue in that repository.
Final question....is it always a rule in Transfer Learning to put the pretrained model (i.e., the model w/ pretrained weights) at the bottom?
Generally it is. Think of the convolution kernels as "features": the first layer detects small edges, colors. The following layers combines those edges and colors into more complicated detections, like "yellow lines" or "blue circle". Then the upper convolution layers detects more abstract shapes as "eyes", "nose", etc. based on detections of lower layers. So replacing the bottom layers (while the upper layers depends on the bottom representation) is illogic.
{kind=link}