I recently started getting into Q-Learning. I'm currently writing an agent that should play a simple board game (Othello). I'm playing against a random opponent. However it is not working properly. Either my agent stays around 50% winrate or gets even worse, the longer I train. The output of my neural net is an 8x8 matrix with Q-values for each move.
My reward is as follows:
- 1 for a win
- -1 for a loss
- an invalid move counts as loss therefore the reward is -1
- otherwise I experimented with a direct reward of -0.01 or 0.
I've made some observations I can't explain: When I consider the prediction for the first move (my agent always starts) the predictions for the invalid moves get really close to -1 really fast. The predictions for the valid moves however seem to rise the longer I play. They even went above 1 (they were above 3 at some point), what shouldn't be possible since I'm updating my Q-values according to the Bellman-equation (with alpha = 1)
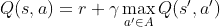
where Gamma is a parameter less than 1 (I use 0.99 for the most time). If a game lasts around 30 turns I would expect max/min values of +-0.99^30=+-0.73.
Also the predictions for the starting state seem to be the highest.
Another observation I made, is that the network seems to be too optimistic with its predictions. If I consider the prediction for a move, after which the game will be lost, the predictions for the invalid turns are again close to -1. The valid turn(s) however, often have predictions well above 0 (like 0.1 or even 0.5).
I'm somewhat lost, as I can't explain what could cause my problems, since I already double-checked my reward/target matrices. Any ideas?