While not optimal, you could try to catch these encodings and replace them with the UTF-8 standard:
newstring = oldstring.replace(re/’/\'/);
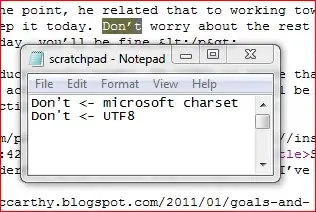
This appears to be a case of a service that specifies UTF-8, but does't explicitly enforce it. I uploaded an image of the RSS feed that you provided. For comparison, I cut and pasted the text into a notepad document and then typed in the same text from my keyboard.
I don't know if you can tell from the image, but the apostrophe that is mangled is different from the apostrophe that is generated by my UTF-8 browser.
I suspect that this post was submitted via a Windows client. If you look at your encoding options, you will see an option for Western (Windows-1252).
Windows-1252 is a legacy encoding from windows that resembles ISO 8859-1, but substitutes some of their own characters for control characters in the ANSI standard and changes the location in the codepage of others.
A couple of quotes from the wikipedia page that I cite above:
It is very common to mislabel Windows-1252 text data with the charset label ISO-8859-1. Many web browsers and e-mail clients treat the MIME charset ISO-8859-1 as Windows-1252 characters in order to accommodate such mislabeling
Many Microsoft programs, such as Word will automatically substitute Windows-1252 characters when standard ASCII characters are entered, such as for "smart quotes" (e.g. substituting ’ for the apostrophe in a contraction) or substituting © for the three characters '(c)'.
KRL supports all of the language charsets supported by UTF-8, so it supports multi-byte international characters natively; however, that comes at the expense of being able to fudge encodings that is possible when you only have ISO-8859-1 or Windows-1252 to choose from.
