I have a time series of data that has values that represent 'activity' collected by the minute. I set up an LSTM in order to model the data. The LSTM is set to input 300 points, and output the next 60 points.
I've tweaked the architecture of the LSTM slightly, but the loss usually converges after one epoch and the prediction seems to be the same 60 points for any 300 input.
Is there anything wrong with my code or general approach?
n_test = int(df.shape[0] * 0.2)
n_in = 300
n_out = 60
n_batch = 1
n_epochs = 3
verbose = 1
neurons = (5,5)
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = pd.DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
def prepare_data(series, n_test, n_lag, n_seq):
raw_values = series.values
raw_values = raw_values.reshape(len(raw_values), 1)
scaler = MinMaxScaler(feature_range=(-1, 1))
scaled_values = scaler.fit_transform(raw_values)
# series_to_supervised is above
supervised = series_to_supervised(scaled_values, n_lag, n_seq)
supervised_values = supervised.values
train, test = supervised_values[0:-n_test], supervised_values[-n_test:]
return scaler, train, test
scaler, train, test = prepare_data(df, n_test, n_in, n_out)
def fit_lstm(train, test, n_lag, n_seq, n_batch, nb_epoch, n_neurons, verbose):
# reshape training into [samples, timesteps, features]
X, y = train[:, :n_lag], train[:, n_lag:]
X = X.reshape(X.shape[0], 1, X.shape[1])
X_test, y_test = test[:, :n_lag], test[:, n_lag:]
X_test = X_test.reshape(X_test.shape[0], 1, X_test.shape[1])
model = Sequential()
model.add(LSTM(n_neurons[0], batch_input_shape=(n_batch, X.shape[1], X.shape[2]),
return_sequences=True, stateful=True, dropout=0.4))
model.add(LSTM(n_neurons[1], batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(y.shape[1]))
model.compile(loss='mse', optimizer='adam')
losses = []
val_losses = []
min_val_loss = (99999,999999)
for i in range(nb_epoch):
if verbose!=0:
print(i)
history = model.fit(X, y, validation_data=(X_test,y_test), epochs=1, batch_size=n_batch, verbose=verbose, shuffle=False)
losses.append(history.history['loss'])
val_losses.append(history.history['val_loss'][0])
if val_losses[-1] < min_val_loss[0]:
min_val_loss = (val_losses[-1], i)
model.reset_states()
print('best val_loss and epoch:',min_val_loss)
plt.title('loss')
plt.plot(losses)
plt.plot(val_losses, color='red')
plt.show()
return model
model = fit_lstm(train, test, n_in, n_out, n_batch, n_epochs, neurons, verbose)
# Running on 3 epochs:
# Train on 420005 samples, validate on 105091 samples
# Epoch 1/1
# 420005/420005 [==============================] - 1183s - loss: 0.0143 - val_loss: 0.0086
# Train on 420005 samples, validate on 105091 samples
# Epoch 1/1
# 420005/420005 [==============================] - 1185s - loss: 0.0142 - val_loss: 0.0086
# Train on 420005 samples, validate on 105091 samples
# Epoch 1/1
# 420005/420005 [==============================] - 1179s - loss: 0.0142 - val_loss: 0.0086
def forecast_lstm(model, X, n_batch):
X = X.reshape(1, 1, len(X))
model.reset_states()
forecast = model.predict(X, batch_size=n_batch, verbose=0)
model.reset_states()
return [x for x in forecast[0, :]]
def make_forecasts(model, n_batch, points, n_lag, n_seq):
forecasts = list()
for i in range(len(points)):
X = points[i, 0:n_lag]
forecast = forecast_lstm(model, X, n_batch)
forecasts.append(forecast)
return forecasts
forecasts = make_forecasts(model, n_batch, test, n_in, n_out)
def inverse_transform(forecasts, scaler):
inverted = list()
for i in range(len(forecasts)):
forecast = np.array(forecasts[i])
forecast = forecast.reshape(1, len(forecast))
inv_scale = scaler.inverse_transform(forecast)
inv_scale = inv_scale[0, :]
inverted.append(list(inv_scale))
return inverted
forecasts = inverse_transform(forecasts, scaler)
actual = inverse_transform(test, scaler)
def evaluate_forecasts(test, forecasts, n_lag, n_seq):
total_rmse = 0
if type(test) is list:
test = np.array(test)
for i in range(n_seq):
actual = test[:,(n_lag+i)]
predicted = [forecast[i] for forecast in forecasts]
rmse = np.sqrt(mean_squared_error(actual, predicted))
print('t+%d RMSE: %f' % ((i+1), rmse))
total_rmse += rmse
print('total rmse: ', total_rmse)
evaluate_forecasts(actual,forecasts,n_in, n_out)
# t+1 RMSE: 155.838490
# t+2 RMSE: 168.965727
# t+3 RMSE: 167.270456
# t+4 RMSE: 176.760815
# t+5 RMSE: 127.637996
# t+6 RMSE: 186.222487
# t+7 RMSE: 160.867497
# t+8 RMSE: 131.757333
# t+9 RMSE: 171.576859
# t+10 RMSE: 164.078086
# t+11 RMSE: 189.710840
# t+12 RMSE: 135.071027
# t+13 RMSE: 176.108870
# t+14 RMSE: 123.596369
# t+15 RMSE: 176.243116
# t+16 RMSE: 158.860359
# t+17 RMSE: 146.936220
# t+18 RMSE: 146.639956
# t+19 RMSE: 153.618794
# t+20 RMSE: 147.312042
# t+21 RMSE: 149.182079
# t+22 RMSE: 138.054920
# t+23 RMSE: 145.804312
# t+24 RMSE: 166.382771
# t+25 RMSE: 143.922779
# t+26 RMSE: 156.105344
# t+27 RMSE: 115.304277
# t+28 RMSE: 135.514702
# t+29 RMSE: 154.820486
# t+30 RMSE: 188.279115
# t+31 RMSE: 138.019347
# t+32 RMSE: 160.715638
# t+33 RMSE: 173.415381
# t+34 RMSE: 180.411886
# t+35 RMSE: 145.646395
# t+36 RMSE: 128.124628
# t+37 RMSE: 164.583304
# t+38 RMSE: 182.525903
# t+39 RMSE: 145.345988
# t+40 RMSE: 172.166096
# t+41 RMSE: 129.625155
# t+42 RMSE: 137.745757
# t+43 RMSE: 198.990463
# t+44 RMSE: 166.928849
# t+45 RMSE: 171.436070
# t+46 RMSE: 186.811325
# t+47 RMSE: 144.422246
# t+48 RMSE: 156.781829
# t+49 RMSE: 172.120825
# t+50 RMSE: 149.682804
# t+51 RMSE: 141.673213
# t+52 RMSE: 172.357648
# t+53 RMSE: 158.622753
# t+54 RMSE: 184.421916
# t+55 RMSE: 171.320013
# t+56 RMSE: 106.285773
# t+57 RMSE: 114.165503
# t+58 RMSE: 124.827654
# t+59 RMSE: 102.873840
# t+60 RMSE: 134.097910
# total rmse: 9274.59023828
def plot_forecasts(series, test, forecasts, n_in, n_out):
t = pd.DataFrame(test)
f = pd.DataFrame(forecasts)
t.iloc[:,n_in:n_in+n_out] = f.values
t['idx'] = len(series) + t.index.values - n_in - len(test) -n_out
# plot the forecasts in red
for i in range(len(forecasts)):
xaxis = np.array([t.loc[i,'idx']] * (n_in+n_out)) + np.array(range((n_in+n_out)))
yaxis = t.iloc[i,:-1].values
plt.plot(xaxis, yaxis, color='red')
# plot the entire dataset in blue
plt.plot(series.values)
plt.show()
plot_forecasts(train,actual,forecasts[-1],n_in,n_out)
Images:
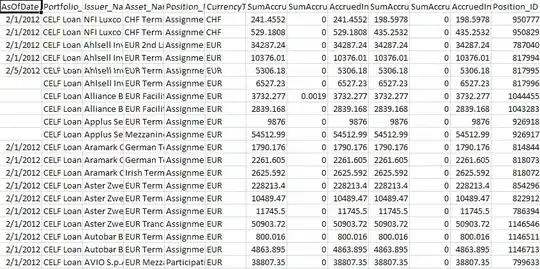
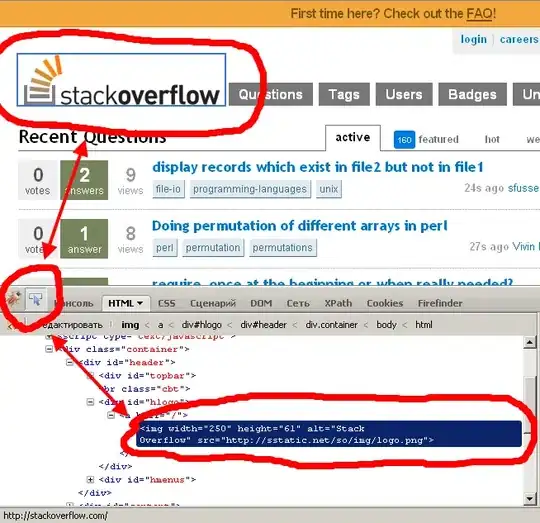
Above is a plot of the latest prediction (of the test set: need to use 360 points, where the first 300 are the input to the LSTM, and the last 60 will be compared to the forecast shown in red). For any point I put in, that same jagged line at around value 200 is outputted. Here is a zoomed in look using a different 300 points:
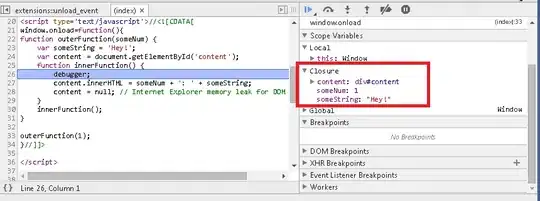
After removing the model.reset_states() in forecast, the RMSEs reduced to and the graph looks different:
t+1 RMSE: 56.001612
t+2 RMSE: 55.304949
t+3 RMSE: 54.572932
t+4 RMSE: 53.878164
t+5 RMSE: 53.252430
t+6 RMSE: 52.709159
t+7 RMSE: 52.188684
t+8 RMSE: 51.722300
t+9 RMSE: 51.298685
t+10 RMSE: 50.909361
t+11 RMSE: 50.534432
t+12 RMSE: 50.153235
t+13 RMSE: 49.843989
t+14 RMSE: 49.544826
t+15 RMSE: 49.251911
t+16 RMSE: 48.953321
t+17 RMSE: 48.736308
t+18 RMSE: 48.524235
t+19 RMSE: 48.319380
t+20 RMSE: 48.123144
t+21 RMSE: 47.924274
t+22 RMSE: 47.724813
t+23 RMSE: 47.548941
t+24 RMSE: 47.430078
t+25 RMSE: 47.320304
t+26 RMSE: 47.237417
t+27 RMSE: 47.138287
t+28 RMSE: 47.041020
t+29 RMSE: 46.933505
t+30 RMSE: 46.832966
t+31 RMSE: 46.733669
t+32 RMSE: 46.637092
t+33 RMSE: 46.564030
t+34 RMSE: 46.419809
t+35 RMSE: 46.220688
t+36 RMSE: 46.112665
t+37 RMSE: 46.053153
t+38 RMSE: 45.999633
t+39 RMSE: 45.950166
t+40 RMSE: 45.903748
t+41 RMSE: 45.861863
t+42 RMSE: 45.825802
t+43 RMSE: 45.798098
t+44 RMSE: 45.776262
t+45 RMSE: 45.702105
t+46 RMSE: 45.659707
t+47 RMSE: 45.613096
t+48 RMSE: 45.577615
t+49 RMSE: 45.554801
t+50 RMSE: 45.531822
t+51 RMSE: 45.506663
t+52 RMSE: 45.485158
t+53 RMSE: 45.461476
t+54 RMSE: 45.400751
t+55 RMSE: 45.365654
t+56 RMSE: 45.334558
t+57 RMSE: 45.316315
t+58 RMSE: 45.300184
t+59 RMSE: 45.253731
t+60 RMSE: 45.223637
total rmse: 2870.0986146
Images:
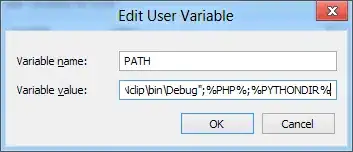

Edit: Adding in a few more points and the output. The same 60 points are being output for any 300 input.