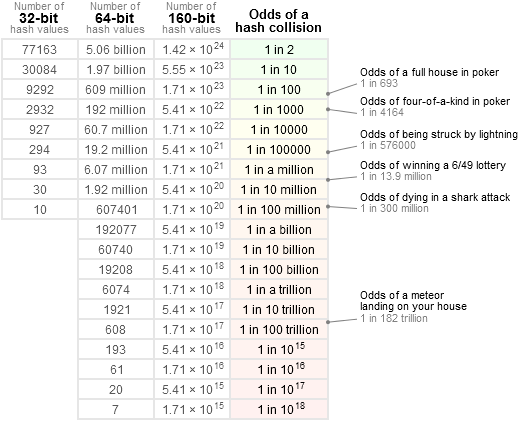
I typically wouldn't use a 32-bit hash except for very low cardinality because it of course risks collisions a lot more than a 64-bit hash would. Databases readily support bigint 8-byte (64-bit) integers. Consider this table for some hash collision probabilities.
If you're using Python ≥3.6, you absolutely don't need to use a third-party package for this, and you don't need to subtract an offset either, since you can directly generate a signed 64-bit or variable bit-length hash utilizing shake_128:
import hashlib
from typing import Dict, List
class Int8Hash:
BYTES = 8
BITS = BYTES * 8
BITS_MINUS1 = BITS - 1
MIN = -(2**BITS_MINUS1)
MAX = 2**BITS_MINUS1 - 1
@classmethod
def as_dict(cls, texts: List[str]) -> Dict[int, str]:
return {cls.as_int(text): text for text in texts} # Intentionally reversed.
@classmethod
def as_int(cls, text: str) -> int:
seed = text.encode()
hash_digest = hashlib.shake_128(seed).digest(cls.BYTES)
hash_int = int.from_bytes(hash_digest, byteorder='big', signed=True)
assert cls.MIN <= hash_int <= cls.MAX
return hash_int
@classmethod
def as_list(cls, texts: List[str]) -> List[int]:
return [cls.as_int(text) for text in texts]
Usage:
>>> Int8Hash.as_int('abc')
6377388639837011804
>>> Int8Hash.as_int('xyz')
-1670574255735062145
>>> Int8Hash.as_list(['p', 'q'])
[-539261407052670282, -8666947431442270955]
>>> Int8Hash.as_dict(['i', 'j'])
{8695440610821005873: 'i', 6981288559557589494: 'j'}
To generate a 32-bit hash instead, set Int8Hash.BYTES to 4.
Disclaimer: I have not written a statistical unit test to verify that this implementation returns uniformly distributed integers.
{kind=link}