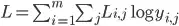I have a neural network, trained on MNIST, with categorical cross entropy as its loss function.
For theoretical purposes my output layer is ReLu. Therefore a lot of its outputs are 0.
Now I stumbled across the following question:
Why don't I get a lot of errors, since certainly there will be a lot of zeros in my output, which I will take the log of.
Here, for convenience, the formula for categorical cross entropy.