If I look at the image I am tempted to conclude this series has something like a power law behavior, but to say this you need to prove it has 1/f noise.
Let's see if we can verify this assumption:
Build a noise model for 1/f noise: scale / (1 + f ** alpha). This is a mathematical model of 1/f niose with parameters scale (the amplitude) and alpha (describes the ratio of high to low frequencies)
Fit the noise model to the data (in this case fit it to the power spectral density)
Inspect the result. Does it look like the model describes tha data well? If not - try to find a different niose model. But beware of overfitting!
Snip:
from scipy.optimize import curve_fit
import numpy as np
import matplotlib.pyplot as plt
data1 = np.array([1, 0.28571429, 0.20408163, 0.16326531, 0.14285714,
0.10204082, 0.08163265, 0.06122449, 0.04081633, 0.02040816])
def one_over_f(f, alpha, scale):
return scale / f ** alpha
time_step = 1 / 30
ps1 = np.abs(np.fft.fft(data1)) ** 2
freqs1 = np.fft.fftfreq(data1.size, time_step)
# remove the DC bin because 1/f cannot fit at 0 Hz
ps1 = ps1[freqs1 != 0]
freqs1 = freqs1[freqs1 != 0]
params, _ = curve_fit(one_over_f, np.abs(freqs1), ps1)
ps2 = one_over_f(freqs1, *params)
idx1 = np.argsort(freqs1)
fig, ax = plt.subplots()
ax.plot(freqs1[idx1], ps1[idx1], color='red', label='data1')
ax.plot(freqs1[idx1], ps2[idx1], color='blue', label='fit')
plt.grid(True, which="both")
ax.set_yscale('log')
ax.set_xscale('log')
plt.xlabel("Frequency")
plt.ylabel("Power")
plt.xlim(0,15)
plt.legend()
print('Alpha:', params[0], '\nScale:', params[1])
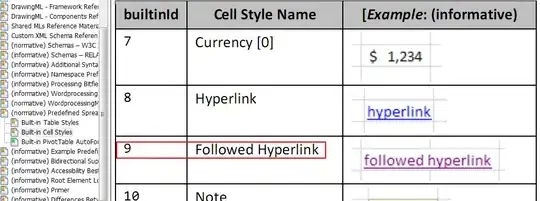
Visually, the model appears to fit the 1/f spectrum very well. This is not a proof. It is really hard to prove that data has a certain distribution. But you can judge for yourself if a chosen noise model visually fits the data good enough for your needs.

