This is my first time using python, so I'm having lots of doubts.
I'm trying to make a simple ANN for forecasting in Pybrain. It is a 2 input-1 output net. The inputs are, in the first column has the years and the second column has the months of the year. The outputs are the normal rainfall, linked to each month.
I don't know how many things I am doing wrong, but when I plot the results, I'm having errors.
This is my code:
from pybrain.datasets import SupervisedDataSet
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.tools.validation import ModuleValidator
from pybrain.structure import SigmoidLayer, LinearLayer,TanhLayer
from pybrain.utilities import percentError
import matplotlib.pyplot as plt
import numpy as np
import math
#----------------------------------------------------------------------------------------------------------------------
if __name__ == '__main__':
ds = SupervisedDataSet(2,1)
input = np.loadtxt('entradas.csv', delimiter=',')
output = np.loadtxt('salidas.csv', delimiter=',')
for x in range(0, len(input)):
ds.addSample(input[x], output[x])
print (ds['input'])
print ("Hay una serie de",len(ds['target']),"datos")
#print(ds)
# Definicion topologia de la Red Neuronal
n = buildNetwork(ds.indim,5,ds.outdim,recurrent=True,hiddenclass=SigmoidLayer)
#ENTRENAMIENTO DE LA RED NEURONAL
trndata,partdata=ds.splitWithProportion(0.60)
tstdata,validata=partdata.splitWithProportion(0.50)
print ("Datos para Validacion:",len(validata))
print("Datos para Test:", len(tstdata))
print("Datos para Entrenamiento:", len(trndata))
treinadorSupervisionado = BackpropTrainer(n, dataset=trndata,momentum=0.1,verbose=True,weightdecay=0.01)
numeroDeEpocasPorPunto = 100
trnerr,valerr=treinadorSupervisionado.trainUntilConvergence(dataset=trndata,maxEpochs=numeroDeEpocasPorPunto)
max_anno = input.max(axis=0)[0]
min_anno = input.min(axis=0)[0]
max_precip = output.max()
min_precip = output.min()
print("El primer año de la serie temporal disponible es:", min_anno)
print("El ultimo año de la serie temporal disponible es:", max_anno)
print("La máxima precipitación registrada en la serie temporal es:", max_precip)
print("La mínima precipitación registrada en la serie temporal es:", min_precip)
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
plt.xlabel('número de épocas')
plt.ylabel(u'Error')
plt.plot(trnerr,'b',valerr,'r')
plt.show()
treinadorSupervisionado.trainOnDataset(trndata,50)
print(treinadorSupervisionado.totalepochs)
out=n.activateOnDataset(tstdata).argmax(axis=1)
print(percentError(out,tstdata))
out=n.activateOnDataset(tstdata)
out=out.argmax(axis=1)
salida=n.activateOnDataset(validata)
salida=salida.argmax(axis=1)
print(percentError(salida,validata))
print ('Pesos finales:', n.params)
#Parametros de la RNA:
for mod in n.modules:
print("Module:", mod.name)
if mod.paramdim > 0:
print("--parameters:", mod.params)
for conn in n.connections[mod]:
print("-connection to", conn.outmod.name)
if conn.paramdim > 0:
print("- parameters", conn.params)
if hasattr(n, "recurrentConns"):
print("Recurrent connections")
for conn in n.recurrentConns:
print("-", conn.inmod.name, " to", conn.outmod.name)
if conn.paramdim > 0:
print("- parameters", conn.params)
And this is the plot I get after running the code:
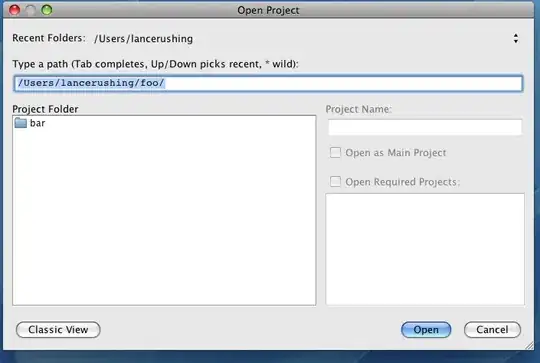
Where the blue line is the training error and the red line is the validation error.
This doesn't make any sense. I have searched other questions, but I still don't know why I'm having this result.
My desired result is to predict, for example, the rainfall for each month in the following years, for example for 2010 (the series go from 1851 until 2008).