References
Calculating coskew
My interpretation of coskew is the "correlation" between one series and the variance of another. As such, you can actually have two types of coskew depending on which series we are calculating the variance of. Wikipedia shows these two formula
'left'
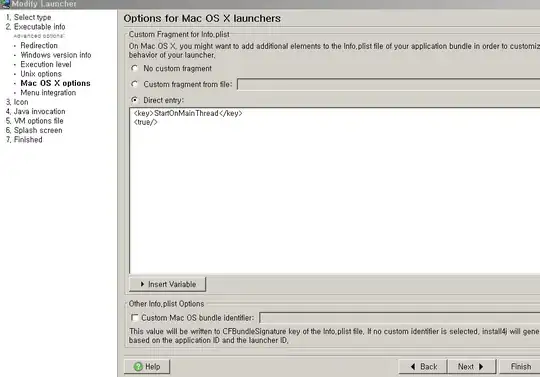
'right'
Fortunately, when we calculate the coskew matrix, one is the transpose of the other.
def coskew(df, bias=False):
v = df.values
s1 = sigma = v.std(0, keepdims=True)
means = v.mean(0, keepdims=True)
# means is 1 x n (n is number of columns
# this difference broacasts appropriately
v1 = v - means
s2 = sigma ** 2
v2 = v1 ** 2
m = v.shape[0]
skew = pd.DataFrame(v2.T.dot(v1) / s2.T.dot(s1) / m, df.columns, df.columns)
if not bias:
skew *= ((m - 1) * m) ** .5 / (m - 2)
return skew
demonstration
coskew(df)
a b
a -0.369380 0.096974
b 0.325311 0.067020
We can compare this to df.skew() and check that the diagonals are the same
df.skew()
a -0.36938
b 0.06702
dtype: float64
Calculating cokurtosis
My interpretation of cokurtosis is one of two
- "correlation" between a series and the skew of another
- "correlation" between the variances of two series
For option 1. we again have both a left and right variant that in matrix form are transposes of one another. So, we will only focus on the left variant. That leaves us with calculating a total of two variations.
'left'
'middle'
def cokurt(df, bias=False, fisher=True, variant='middle'):
v = df.values
s1 = sigma = v.std(0, keepdims=True)
means = v.mean(0, keepdims=True)
# means is 1 x n (n is number of columns
# this difference broacasts appropriately
v1 = v - means
s2 = sigma ** 2
s3 = sigma ** 3
v2 = v1 ** 2
v3 = v1 ** 3
m = v.shape[0]
if variant in ['left', 'right']:
kurt = pd.DataFrame(v3.T.dot(v1) / s3.T.dot(s1) / m, df.columns, df.columns)
if variant == 'right':
kurt = kurt.T
elif variant == 'middle':
kurt = pd.DataFrame(v2.T.dot(v2) / s2.T.dot(s2) / m, df.columns, df.columns)
if not bias:
kurt = kurt * (m ** 2 - 1) / (m - 2) / (m - 3) - 3 * (m - 1) ** 2 / (m - 2) / (m - 3)
if not fisher:
kurt += 3
return kurt
demonstration
cokurt(df, variant='middle', bias=False, fisher=False)
a b
a 1.882817 0.86649
b 0.866490 1.63200
cokurt(df, variant='left', bias=False, fisher=False)
a b
a 1.882817 0.19175
b -0.020567 1.63200
The diagonal should be equal to kurtosis
df.kurtosis() + 3
a 1.882817
b 1.632000
dtype: float64



