k-NN vs. Decision Tree
I always find a picture is the best way to gain an intuition of an algorithm. The target function you suggest would give rise to a data set a bit like this:

Where the function to separate the data is x1 - x2 = 0. The trouble is that normally, decision trees only have functions of one variable at the nodes, so the decision functions at the nodes are axis aligned. I image a decision tree learned on this data set would do something like this:
Hopefully you get the idea, obviously you can approximate the optimal decision boundary by doing this with enough nodes in a decision tree, but that means you run the risk of overfitting the data.
Actually, I said that decision trees normally use single variable functions at nodes, but there is another approach, described in a StackOverflow question about multivariate decision trees (that I failed to answer).
By the way, the best classifier for this kind of data would be a linear classifier, maybe logistic regression, which would find the optimal decision boundary
The effect of k in k-NN
The best description I can give for k in k-nearest neighbour is that high values of k smooth the decision boundary. It is also not the case that a higher k is always better then a lower one.
To think about k-NN we need a bit more of a complicated data set. For k=1, a k-NN model might make decisions a bit like this:
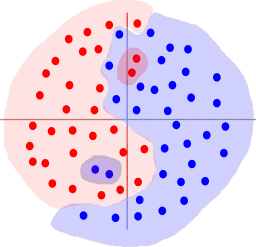
If we increased the value of k, the decisions would be affected by a larger neighbourhood of points and so the decision boundaries would become smoother. In particular, those little red and blue island would be overwhelmed by the surrounding data points:

Whether using a high k is better depends on the level of noise on the dataset. Were those little islands really important and we learned too simple a model that doesn't fit the data very well, or were they just noise and did we avoid overfitting?
A practical perspective
Unfortunately, given some large, complex, real-world data set you probably don't have a very good basis for deciding which algorithm is going to work best (unless you draw on previous work on the same or similar data). What most people do is carefully segment the data into training, parameter tuning and test sets and then run as many algorithms as they can think of. You might also find that you particular situation determines some properties that the algorithm must have (fast, incremental, probabilistic, etc.)