1) does agent need to take action at every discrete time step (1sec) or agent can get an action at every 100m instead of every discrete time step. Is that a must to take action at every discrete time step?
I think you may be confusing the concept of time step in Q-learning with our physical realization of time. In Q-learning, each time step is a time when it's the agent's turn to make a move/take an action. So if the game is chess, then every time step would be when it's the player's time to play. So how frequent your agent can take an action is decided by the rules of the game. In your example, it's not quite clear to me that what the rules of the "game" are? If the rules say the agent gets to pick an action every 1 "second", then the agent will need to follow that. If you think that's too frequent, you can see if "None" is an available action option for the agent to take or not.
what is mean by delayed reward in Q-learning? is that updating reward once agent reaches to the target instead of updating reward after taking each action at every time step?
To understand delayed reward, perhaps take a look at the formula would help.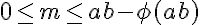 As you can see, the Q value at time step t is not only impacted by the old Q value and immediate reward but also by the "estimated optimal future value". This estimated optimal value (with a hyperparameter discount factor to be tuned) is set to capture the "delayed reward".
As you can see, the Q value at time step t is not only impacted by the old Q value and immediate reward but also by the "estimated optimal future value". This estimated optimal value (with a hyperparameter discount factor to be tuned) is set to capture the "delayed reward".
The intuition behind delayed reward is that sometimes one action may seem to be a bad action to take at that time (mathematically by taking this action the agent received a low immediate reward or even penalty), but somehow this action leads to a long term benefit. Put it in your example, assume the agent is at position P, there are two routes to get to the stop-line. One route has a straight distance of 1 km, the other has a bit of detour and has a distance of 1.5 km. The agent takes the 1.5 km route, it would perhaps receive less immediate reward than picking the 1 km route. Let's further assume that the 1.5 km route has a higher speed limit than the 1 km route, which actually leads the agent to get to the stop line faster than taking the 1 km route. This "future reward" is the delayed reward which needs to be taken into account when calculating the Q value of (state at position P , action of taking 1.5 km route) at time step t.
The formula could be a bit confusing to implement since it involves a future Q value. The way I did it once was simply computing the Q-value at time step t without worrying about the delayed reward.
# @ time step t
Q(st, at) = Q(st, at) + alpha * immedate_reward - alpha*Q(st, at)
Then after reaching time step t+1, I went back to update the previous Q-value at time step t with delayed reward.
# @ time step t+1
Q(st+1, at+1) = Q(st+1, at+1) + alpha * immedate_reward - alpha*Q(st+1, at+t)
Q(st, at) = Q(st, at) + alpha * gama * max(Q(st+1, a))
I hope this helps clarify and answers your question...
