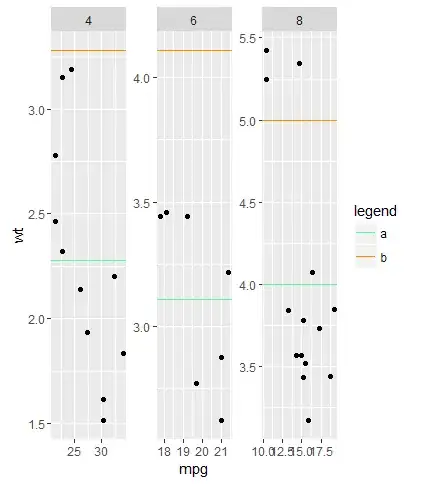
I am experimenting with deploying TF Serving on GKE and trying to make a highly available online prediction system. I was trying to optimize latency by batching multiple requests together. However, the latency seems to suffer rather than improve.
- The model is a CNN, input vector of length around 50.
- TF Serving runs on a Kubernetes cluster with 6 standard nodes
- I tried batches of size 5 and 10. I didn't use the batching implementation from TF Serving, I simply sent a request with an array of shape
(batch_size, input_size)instead of(1, input_size)
My intuition was that even though batching brings most benefit when used with GPUs to use their throughput, using it with CPUs shouldn't make it slower. The slowdown is illustrated in the charts bellow - req/s are rather predictions/s i.e. 20 would be split into either 4 or 2 requests to the server.
I understand how this doesn't spread the workload evenly over the cluster for a smaller number of requests - but even when looking at 60 or 120 the latency is just higher.
Any idea why that is the case?