I'm trying to maximize Sharpe's ratio using scipy.minimize
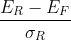
I do this for finding CAPM's Security Market Line
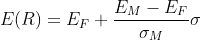
So I have an equation:
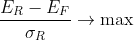

Optional (if short positions is not allowed):
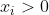
So I'm trying solve this:
def target_func(x, cov_matix, mean_vector, virtual_mean):
f = float(-(x.dot(mean_vector) - virtual_mean) / np.sqrt(x.dot(cov_matix).dot(x.T)))
return f
def optimal_portfolio_with_virtual_mean(profits, virtual_mean, allow_short=False):
x = np.zeros(len(profits))
mean_vector = np.mean(profits, axis=1)
cov_matrix = np.cov(profits)
cons = ({'type': 'eq',
'fun': lambda x: np.sum(x) - 1})
if not allow_short:
bounds = [(0, None,) for i in range(len(x))]
else:
bounds = None
minimize = optimize.minimize(target_func, x, args=(cov_matrix, mean_vector, virtual_mean,), bounds=bounds,
constraints=cons)
return minimize
But I always get Success: False (iteration limit exceeded). I tried to set maxiter = 10000 option, but it didn't help.
I will be greatful for any help
P.S. I use python 2.7