The function is defined as
void bucketsort(Array& A){
size_t numBuckets=A.size();
iarray<List> buckets(numBuckets);
//put in buckets
for(size_t i=0;i!=A.size();i++){
buckets[int(numBuckets*A[i])].push_back(A[i]);
}
////get back from buckets
//for(size_t i=0,head=0;i!=numBuckets;i++){
//size_t bucket_size=buckets[i].size();
//for(size_t j=0;j!=bucket_size;j++){
// A[head+j] = buckets[i].front();
// buckets[i].pop_front();
//}
//head += bucket_size;
//}
for(size_t i=0,head=0;i!=numBuckets;i++){
while(!buckets[i].empty()){
A[head] = buckets[i].back();
buckets[i].pop_back();
head++;
}
}
//inseration sort
insertionsort(A);
}
where List is just list<double> in STL.
The content of array are generate randomly in [0,1). Theoretically bucket sort should be faster than quicksort for large size for it's O(n),but it fails as in the following graph.
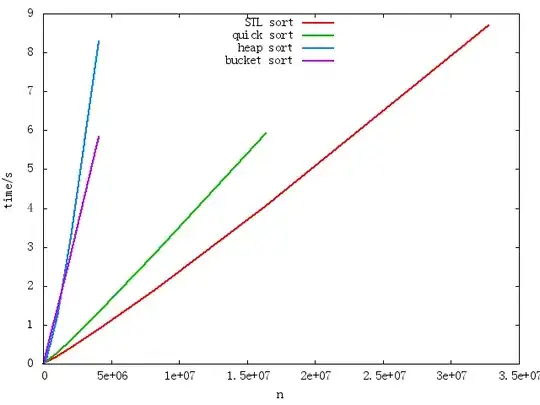
I use google-perftools to profile it on a 10000000 double array. It reports as follow

It seems I should not use STL list,but I wonder why? Which does std_List_node_base_M_hook do? Should I write list class myself?
PS:The experiment and improvement
I have tried just leave the codes of putting in buckets and this explained that most time is used on building up buckets.
The following improvement is made:
- Use STL vector as buckets and reserve reasonable space for buckets
- Use two helper array to store the information used in building buckets,thus avoiding the use of linked list,as in following code
void bucketsort2(Array& A){
size_t numBuckets = ceil(A.size()/1000);
Array B(A.size());
IndexArray head(numBuckets+1,0),offset(numBuckets,0);//extra end of head is used to avoid checking of i == A.size()-1
for(size_t i=0;i!=A.size();i++){
head[int(numBuckets*A[i])+1]++;//Note the +1
}
for(size_t i=2;i<numBuckets;i++){//head[1] is right already
head[i] += head[i-1];
}
for(size_t i=0;i<A.size();i++){
size_t bucket_num = int(numBuckets*A[i]);
B[head[bucket_num]+offset[bucket_num]] = A[i];
offset[bucket_num]++;
}
A.swap(B);
//insertionsort(A);
for(size_t i=0;i<numBuckets;i++)
quicksort_range(A,head[i],head[i]+offset[i]);
}
The result in the following graph
 where line start with list using list as buckets,start with vector using vector as buckets,start 2 using helper arrays.By default insertion sort is used at last and some use quick sort as the bucket size is big.
where line start with list using list as buckets,start with vector using vector as buckets,start 2 using helper arrays.By default insertion sort is used at last and some use quick sort as the bucket size is big.
Note "list" and "list,only put in" ,"vector,reserve 8" and "vector,reserve 2" nearly overlap.
I will try small size with enough memory reserved.