The Inception v3 model is shown in this image:
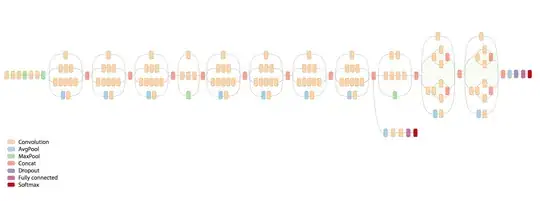
The image is from this blog-post:
https://research.googleblog.com/2016/03/train-your-own-image-classifier-with.html
It seems that there are two Softmax classification outputs. Why is that?
Which one is used in the TensorFlow example as the output tensor with the name 'softmax:0' in this file?
The academic paper for the Inception v3 model doesn't seem to have this image of the Inception model:
http://arxiv.org/pdf/1512.00567v3.pdf
I'm trying to understand why there are these two branches of the network with seemingly two different softmax-outputs.
Thanks for any clarification!